Introducing Context Parallelism
Table of Contents
In the previous analysis of sequence parallelism, I covered two papers 1 2. Those are early works about sequence parallelism and didn’t get attention as there was low demand for context parallelism. After LLMs are required to have longer context support, new papers that tackle the problems of such early works have been emerged.
What are the Problems of Early Sequence Parallelism Works? #

Both works follow the traditional attention computation: compute QK^T, apply mask. softmax, and dropout, then multiply by value to create attention score.
Here, we need a temporary buffer to hold attention weights (TxT), which is huge when we try to compute attention for long sequences.
FlashAttention 3 was introduced to solve the exact same problem by using online softmax 4, gradually aggregating local attention results to compute the final attention results.
Recent SP works are compatible with FlashAttention, distinguishing themselves from early SP works.
Context Parallelism #
Context Parallelism vs Sequence Parallelism #
Why suddenly we say context parallelism instead of sequence parallelism? This is for the purpose of distinguishing standalone sequence parallelism from NVIDIA’s sequence parallelism tied with tensor parallelism 5.
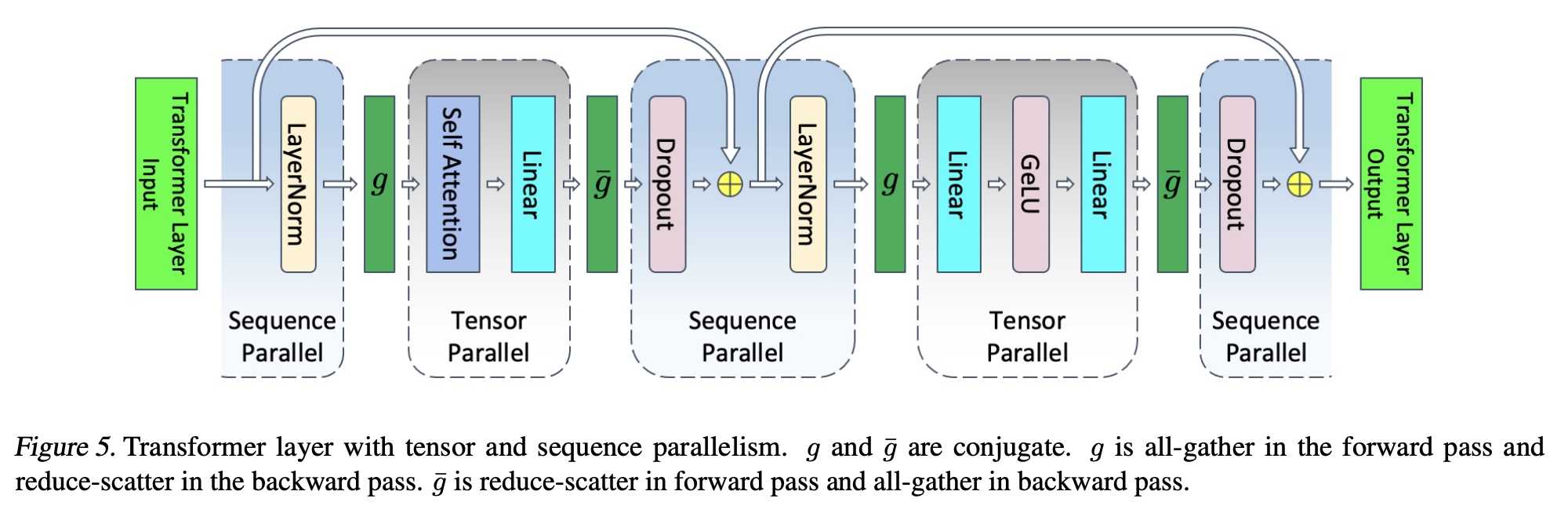
NVIDIA’s sequence parallelism focuses on that tensor parallelism can only be applied to self attention and MLP; for the other part, the model works like data parallelism. Parallelizing those parts can be done without any communication overheads by splitting existing all-reduce to all-gather and reduce-scatter.
However, it needs to be used together with tensor parallelism. Therefore, a type of parallelism that can be used standalone is called context parallelism. Meta also used Context Parallelism (CP) in Llama 3 technical report.
Early works 1 2 can also be said as context parallelism, as they can work without tensor parallelism. From here, I use “context parallelism” only.
Modern Context Parallelism #
There are two works of context parallelism that solves the problem of early context parallelism works:
and a combination of them as 2D context parallelism:
Here, I only introduce Ulysses and RingAttention. LoongTrain and USP can easily be understood once you get the idea of those two works.
Basics of context parallelism: parallelize a long sequence training/inference prefill by partitioning the sequence into multiple subsets of tokens.
Each GPU works on a different set of tokens; to keep the context and relationship between tokens, they need to communicate to compute attention exactly the same as local attention computation.
Ulysses 6 #
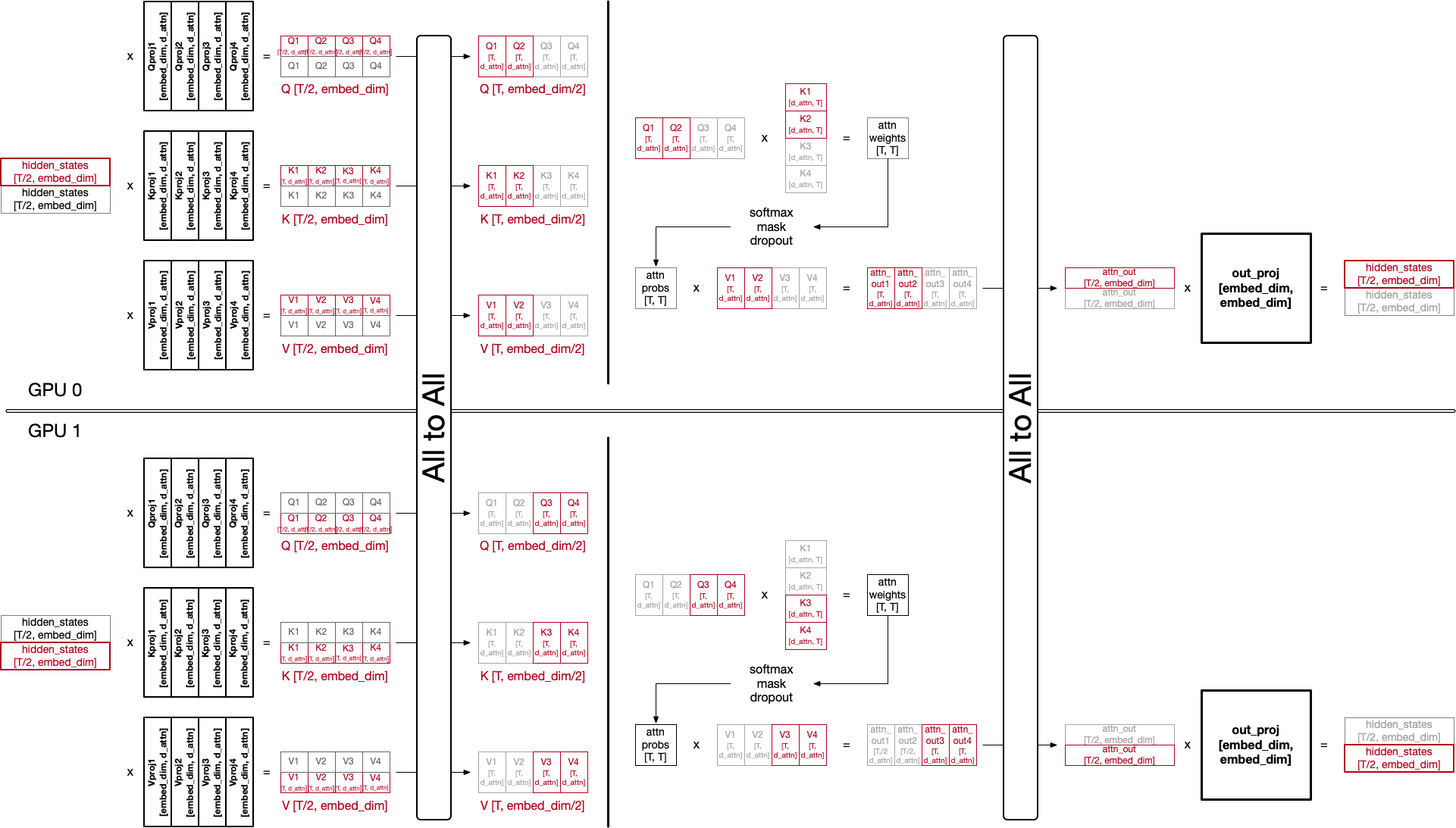
DeepSpeed Ulysses is actually not relevant to FlashAttention and its optimization, but it is compatible and can be used together.
Each GPU has a portion of hidden states partitioned into token dimension (each GPU has hidden states for only T/2 tokens in the example above, where T is the total number of tokens in a sequence).
Ulysses leverages all-to-all to change the hidden states partitioned along the token dimension to attention head dimension.
After all-to-all, each GPU has all tokens’ query, key, and values, but only for a portion of attention heads.
With the data, calculating attention output is similar to tensor parallelism.
In tensor parallelism, out_proj is also partitioned and thus multiplying attention output partitioned along the head dimension with partitioned out_proj creates partial hidden states, which then be reduced using all_reduce (see the tensor parallelism analysis).
Here in context parallelism, instead of creating a whole hidden states, we still want to maintain hidden states only for T/2 tokens.
Therefore, perform additional all-to-all after calculating attention outputs to change the hidden states back to be partitioned along the token dimension.
Note that it is not tensor parallelism, thus out_proj is not partitioned. Multiplying it with attn_out for T/2 tokens generates final hidden states for T/2 tokens.
RingAttention 7 #
RingAttention with blockwise transformer is similar to the original ring self attention (RSA), but integrate blockwise attention computation similar to FlashAttention. In other words, it can be said as a distributed FlashAttention.
Origianl RSA computes QK^T first by sending keys to the next GPUs, and then send values again to the next GPUs to compute attention softmax(QK^T)V.
It requires to hold a temporal results of QK^T and needs more communications to send keys and values separately.
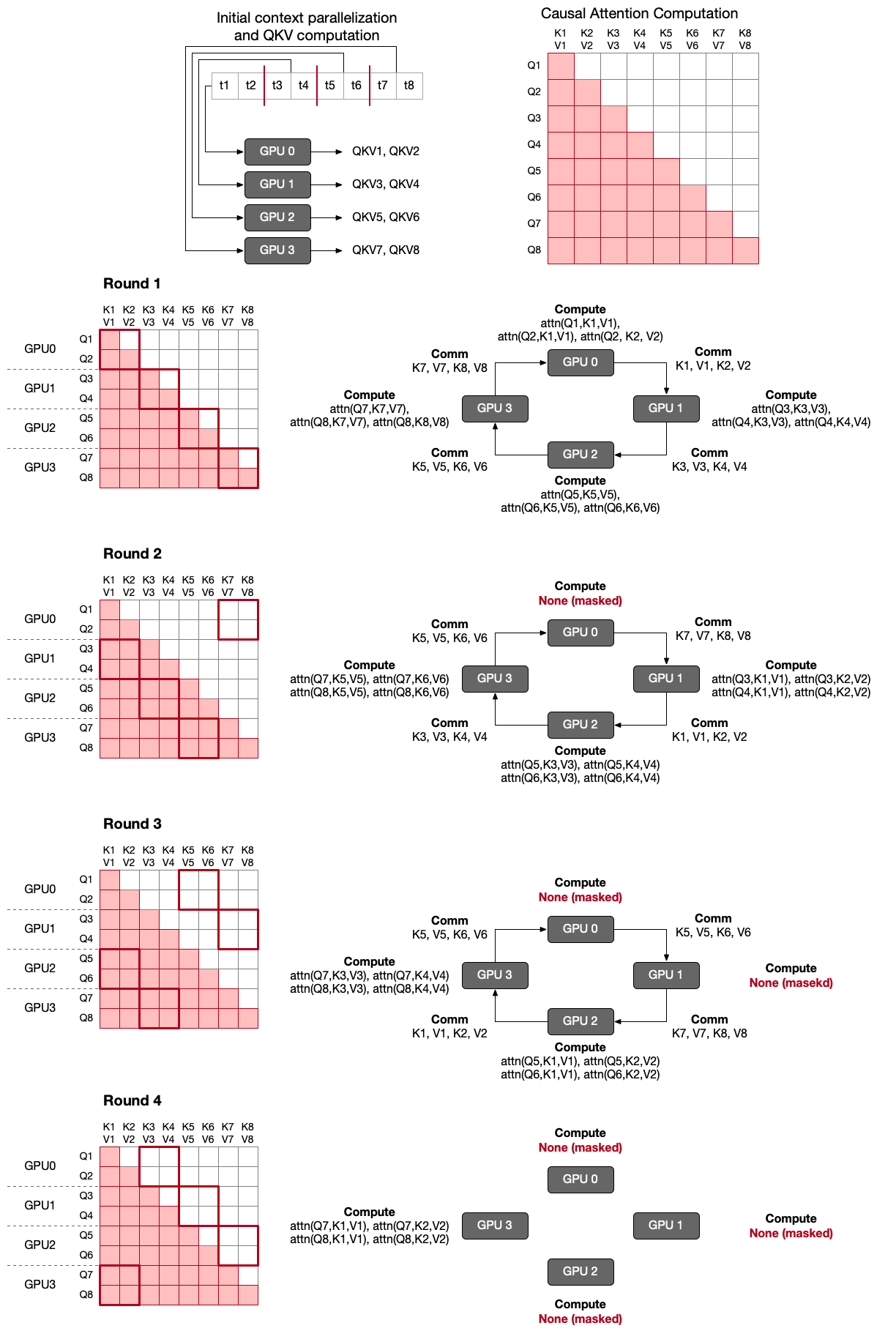
RingAttention, similarly to FlashAttention, gradually accumulates local attention results by iterating Q and K/V as a nested loop. Similarly to RSA, each GPU holds a portion of queries, and sends its keys and values to the next GPU and receives them from the previous GPU (ring).
Unlike RSA, which computes all TxT attention weights and then mask them out, RingAttention with blockwise transformers adopts an optimization not to compute unnecessary masked parts. As a result, for causal attention computation, GPUs have imbalanced amount of computation.
To load balance, DistFlashAttn (reviewed in the previous post) or Striped Attention 10 have been proposed. Let’s have a look at Striped Attention.
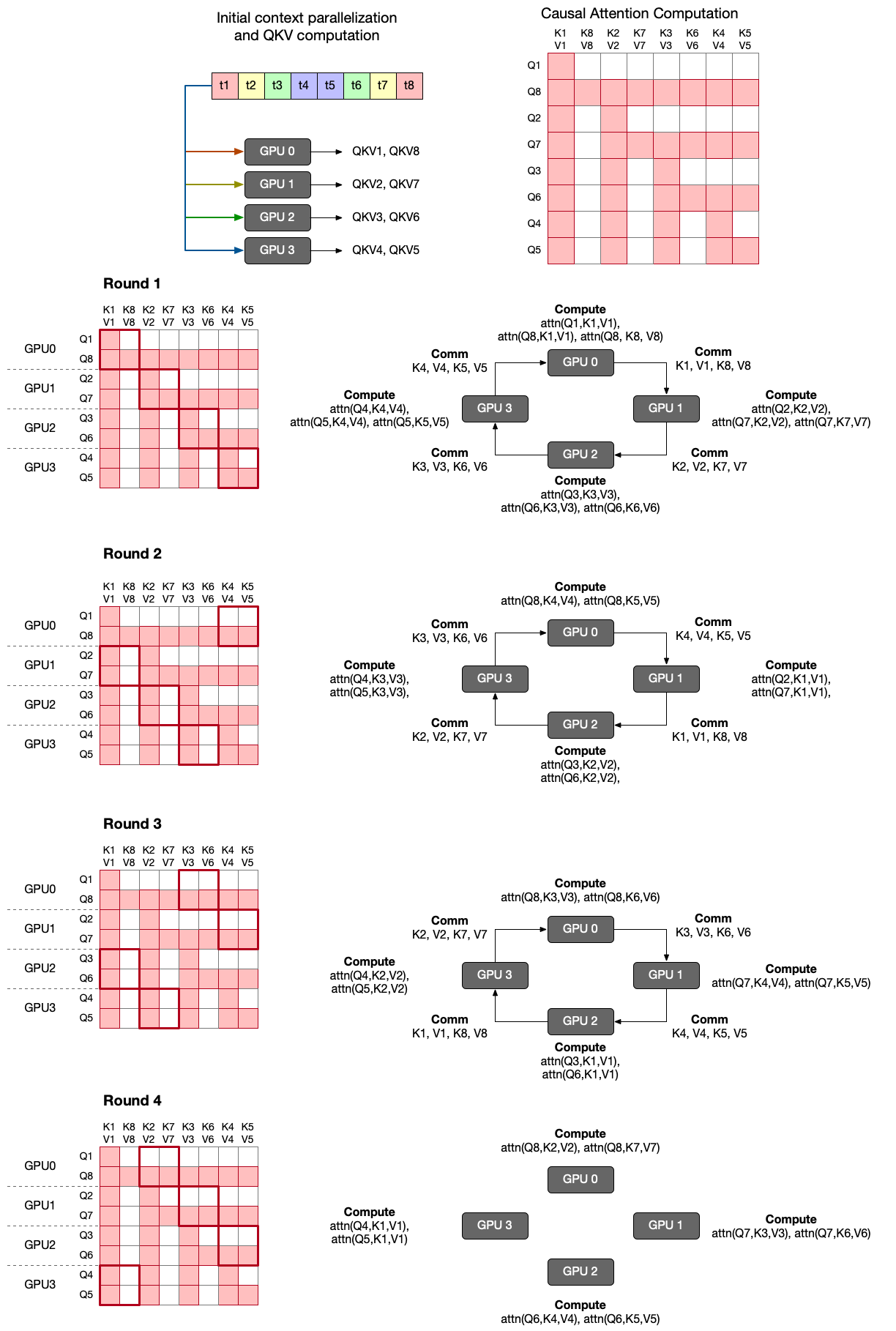
Striped Attention changes the order of tokens in attention calculation for the purpose of load balancing.
It exploits the characteristics of token order: although their positions matter in causal language model, they do not matter in attention computation. Later they are reorganized with position_ids in the model, meaning computing attention can be in any order of tokens.
You can see the order of tokens is changed from t1, t2, ..., t8 to t1, t8, t2, t7, ..., t4, t5.
Although it still needs 4 rounds for computing attention, in each round the amount of computation in each round is reduced and well balanced.
Pros and Cons #
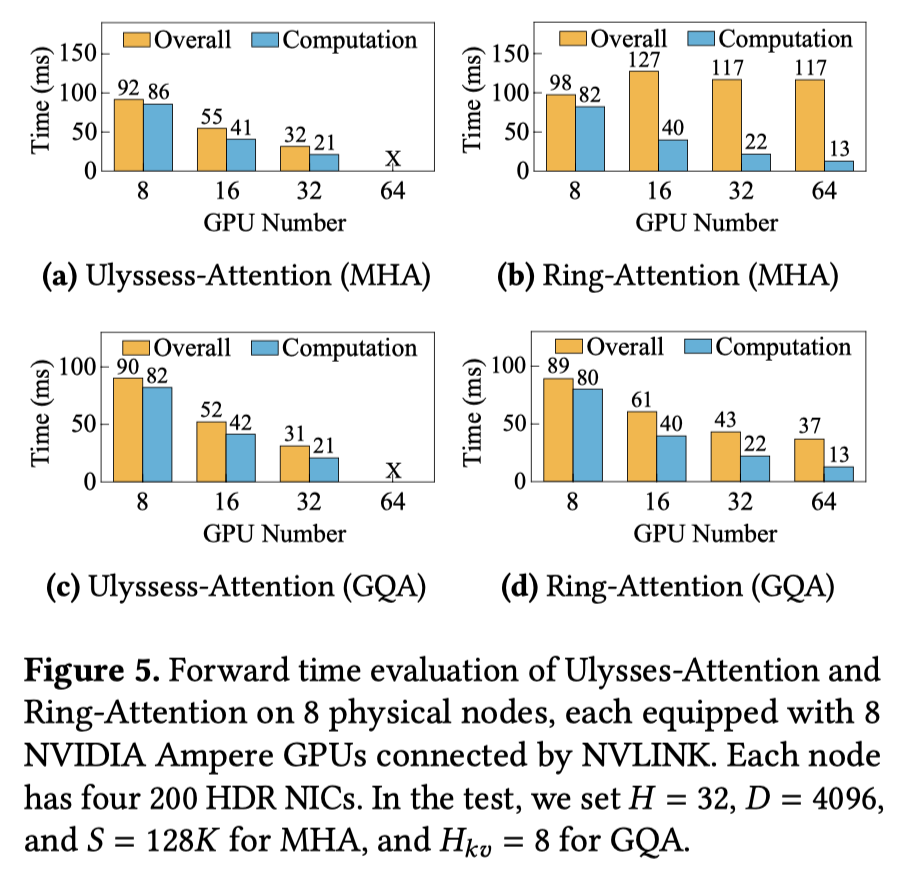
DeepSpeed Ulysses is overall faster while RingAttention suffers from too many communications (Figure above from LoongTrain 8).
However, DeepSpeed Ulysses needs to partition attention heads, its maximum context parallelism degree is limited to the number of attention heads. In the figure above a model has 32 attention heads, thus Ulysses attention with 64 GPUs didn’t work. Moreover, tensor parallelism also partitions the model in the head dimension; thus DeepSpeed Ulysses and tensor parallelism are in conflict. This limits DeepSpeed Ulysses’s scalability. These are main motivations to combine them together to exploit their advantages.
-
Sequence Parallelism: Long Sequence Training from System Perspective ↩︎ ↩︎
-
DISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs Training ↩︎ ↩︎
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness ↩︎
-
Reducing Activation REcomputation in Large Transformer Models ↩︎
-
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models ↩︎ ↩︎
-
RingAttention with Blockwise Transformers for Near-Infinite Context ↩︎ ↩︎
-
LoongTrain: Efficient Training of Long-Sequence LLMs with Head-Context Parallelism ↩︎ ↩︎
-
USP: A Unified Sequence Parallelism Approach for Long Context Generative AI ↩︎
-
Striped Attention: Faster Ring Attention for Causal Transformers ↩︎