Virtio and Vhost Architecture - Part 2
Table of Contents
This post explains overheads of virtio, and introduce vhost that increases performance of virtio.
Virtio Review & Vhost Introduction #
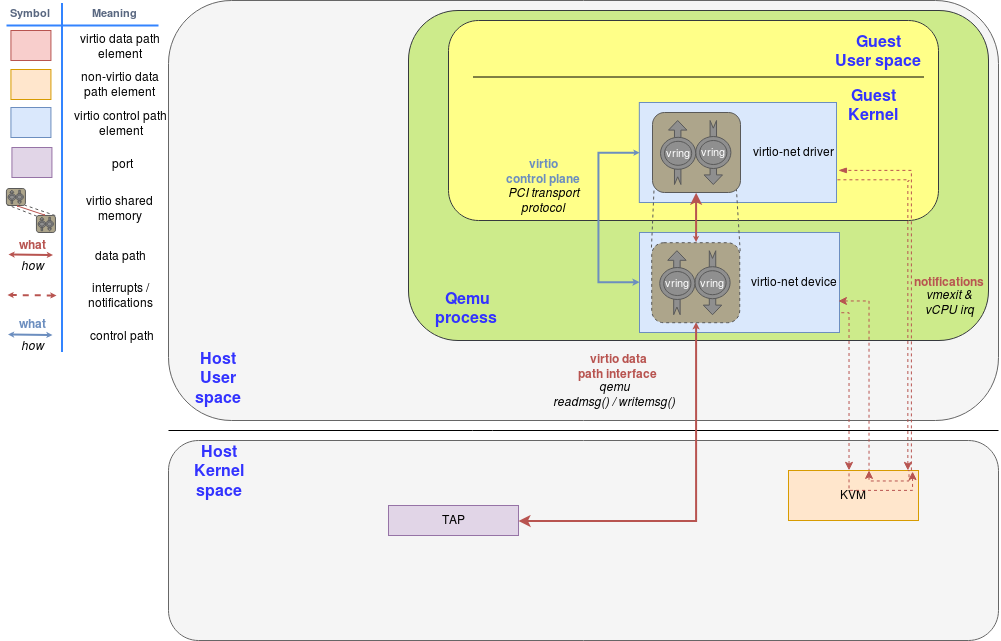
- VirtI/O is implemented with virtqueues, shared by the guest and QEMU process.
- When the guest rings a doorbell after inserting requests into the virtqueue, the context is forwarded to host KVM handler (VM-exit), and again to QEMU process via ioeventfd.
- QEMU process reads the request from the shared virtqueue, and handles it. After completion, QEMU puts the result into the virtqueue and injects an IRQ through irqfd to the guest (4, 5, 6).
- When the guest execution is resumed, the request I/O operation is done and virtio device driver gets result data from the virtqueue (7, 8, 5).
Here, during request handling by QEMU process, several unnecessary context switches happen: to forward the execution context to QEMU process, the guest operating system at first generates a VM-exit, moving to host kernel space, and again to QEMU process via ioeventfd. Then, the QEMU process accesses a tap device (for virtio-net) or a block cdevice (for virtio-blk), forwarding its execution context to host kernel space again.
To reduce context switch overheads, vhost has been introduced to move the location of virtqueue from QEMU process to kernel space.
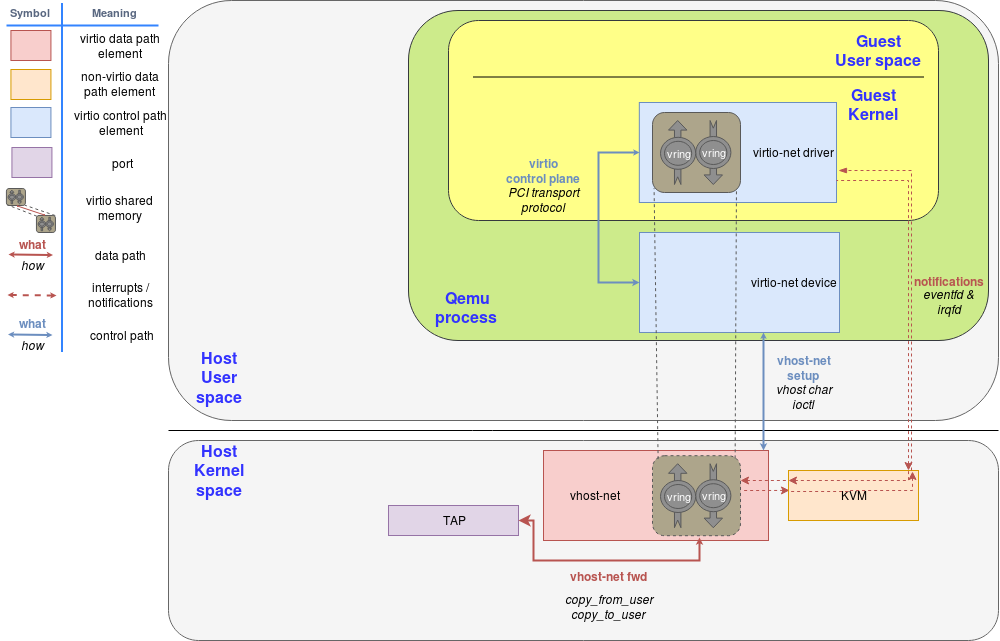
Note I/O requests are handled by vhost-net kernel module, not QEMU process (only setup is done by QEMU process). Only one context switch from the guest kernel space to the host kernel space is required, and any context switches between the host kernel space and host user space (QEMU) is no longer necessary. In other words, vhost is a in-kernel virtio device emulation.
As it only affects back-end device emulation, there is no modification in the guest side: it still uses virtio front-end device driver to access the device.
vhost kernel module is implemented in linux/drivers/vhost, and control plane is implemented in qemu/hw/virtio/vhost*:
// qemu/hw/virtio/vhost-backend.c
static int vhost_kernel_call(struct vhost_dev *dev, unsigned long int request,
void *arg) {
int fd = (uintptr_t) dev->opaque;
return ioctl(fd, request, arg);
}
static int vhost_kernel_net_set_backend(struct vhost_dev *dev,
struct vhost_vring_file *file) {
return vhost_kernel_call(dev, VGOST_NET_SET_BACKEND, file);
}
static int vhost_kernel_set_vring_base(struct vhost_dev *dev,
struct vhost_vring_state *ring) {
return vhost_kernel_call(dev, VHOST_SET_VRING_BASE, ring);
}
/* and many other functions */
static const VhostOps kernel_ops = {
.backend_type = VHOST_BACKEND_TYPE_KERNEL,
.vhost_backend_init = vhost_kernel_init,
...,
.vhost_set_vring_addr = vhost_kernel_set_vring_addr,
.vhost_set_vring_base = vhost_kernel_set_vring_base,
...
};
// qemu/hw/virtio/vhost.c
static int vhost_virtqueue_set_addr(struct vhost_dev *dev,
struct vhost_virtqueue *vq,
unsigned idx, bool enable_log) {
struct bhost_vring_addr addr;
if (dev->vhost_ops->vhost_vq_get_addr) {
dev->vhost_ops->vhost_vq_get_addr(dev, &addr, vq);
}
addr.index = idx;
addr.log_guest_addr = vq->used_phys;
addr.flags = enable_log ? (1 << VHOST_VRING_F_LOG) : 0;
dev->vhost_ops->vhost_set_vring_addr(dev, &addr);
return 0;
}
/* also many other functions here too */
static int vhost_virtqueue_start(...) {
...
vq->num = virtio_queue_get_num(vdev, idex);
dev->vhost_ops->vhost_set_vring_num(dev, &state);
state.num = virtio_queue_get_last_avail_idx(vdev, idx);
dev->vhost_ops->vhost_set_vring_base(dev, &state);
...
vhost_virtqueue_set_addr(dev, vq, vhost_vq_index, dev->log_enabled);
file.fd = event_notifier_get_fd(virtio_queue_get_host_notifier(vvq));
dev->vhost_ops->vhost_set_vring_kick(dev, &file);
...
}
int vhost_dev_start(struct vhost_dev *hdev, VirtIODevice *vdev) {
...
hdev->vhost_ops->vhost_set_mem_table(hdev, hdev->mem);
for (i = 0; i hdev->nvqs; ++i) {
vhost_virtqueue_start(hdev, vdev, hdev->vqs + i, hdev->vq_index + i);
}
hdev->vhost_ops->vhost_dev_start(hdev, true);
...
}
Dataplane Sharing #
In the previous post, I said that Red Hat calls communication with the shared memory (e.g. virtqueue) dataplane. In virtio scenario, sharing memory regions between QEMU process and the guest was simple; but how to share memory area between the guest and the host kernel?
A virtio front-end device driver running in the guest operating system creates virtqueues.
// linux/drivers/virtio/virtio_ring.c
struct virtqueue *vring_new_virtqueue(...) {
struct vring_virtqueue *vq;
vq = kmalloc(sizeof(*vq), GFP_KERNEL);
...
}
How QEMU process know the moment of virtqueue (plus vrings) creation and call ioctl() to register the vrings to vhost-net kernel module?
When virtio-net front-end device driver initializes the device, the status of virtio-net is changed and this is notified to QEMU process:
// qemu/hw/net/virtio-net.c
static NetClientInfo net_virtio_info = {
...,
.link_status_changed = virtio_net_set_link_status,
};
static void virtio_net_set_link_status(NetClientState *nc) {
...
virtio_net_set_status(vdev, vdev->status);
}
static void virtio_net_set_status(struct VirtIODevice *vdev, uint8_t status) {
...
virtio_net_vhost_status(n, status);
...
}
static void virtio_net_vhost_status(VirtIONet *n, uint8_t status) {
...
vhost_net_start(vdev, n->nic->ncs, queues);
}
// qemu/hw/net/vhost_net.c
int vhost_net_start(VirtIODevice *dev, NetClientState *ncs, int total_queues) {
...
for (i = 0; i < total_queues; i++) {
NetClientState *peer = qemu_get_peer(ncs, i);
vhost_net_start_one(get_vhost_net(peer), dev);
if (peer->vring_enable) {
vhost_set_vring_enable(peer, peer->vring_enable);
}
}
...
}
static int vhost_net_start_one(struct vhost_net *net, VirtIODevice *dev) {
...
vhost_dev_enable_notifiers(&net->dev, dev);
vhost_dev_start(&net->dev, dev);
...
}
// qemu/hw/virtio/vhost.c
int vhost_dev_start(struct vhost_dev *hdev, VirtIODevice *vdev) {
...
hdev->vhost_ops->vhost_set_mem_table(hdev, hdev->mem);
for (i = 0; i <hdev->nvqs; ++i) {
vhost_virtqueue_start(hdev, vdev, hdev->vqs + i, hdev->vq_index + i);
}
if (hdev->vhost_ops->vhost_dev_start) {
hdev->vhost_ops->vhost_dev_start(hdev, true);
}
...
}
static int vhost_virtqueue_start(struct vhost_dev* dev,
struct VirtIODevice *vdev,
struct vhost_virtqueue *vq,
unsigned idx) {
...
dev->vhost_ops->vhost_set_vring_num(dev, &state);
dev->vhost_ops->vhost_set_vring_base(dev, &state);
...
/* this internally calls dev->vhost_ops->vhost_set_vring_addr() */
vhost_virtqueue_set_addr(dev, vq, vhost_vq_index, dev->log_enabled);
dev->vhost_ops->vhost_set_vring_kick(dev, &file);
}
and the QEMU here passes vring information to vhost-net kernel module via vhost kernel ioctl() operations.
These requests are handled by vhost kernel module:
// linux/drivers/vhost/vhost.c
long vhost_dev_ioctl(struct vhost_dev *d, unsigned int ioctl, void __user *argp) {
...
switch (ioctl) {
case VHOST_SET_MEM_TABLE: /* implementation omitted */
case VHOST_SET_LOG_BASE: /* ... */
...
}
}
long vhost_vring_ioctl(struct vhost_dev *d, unsigned int ioctl, void __user *argp) {
u32 idx = array_index_nospec(idx, d->nvqs);
struct vhost_virtqueue *vq = d->vqs[idx];
if (ioctl == VHOST_SET_VRING_NUM ||
ioctl == VHOST_SET_VRING_ADDR) {
return vhost_vring_set_num_addr(d, vq, ioctl, argp);
}
switch (ioctl) {
case VHOST_SET_VRING_BASE: /* ... */
case VHOST_SET_VRING_KICK: /* ... */
case VHOST_SET_VRING_CALL: /* ... */
...
}
}
Handling I/O Requests #
Vhost still needs a kick from the guest virtio front-end device driver. When kicked, KVM VM-exit handler handles this kick. Different from virtio that the execution context is forward to QEMU userspace process via ioeventfd, this kick directly notifies vhost kernel module, so that vhost kernel module handles the I/O requests in kernel space without any context switches between host userspace and host kernel space.
Other posts 1 2 say that ioeventfd is used for notification, however, I could not find any implementation in vhost kernel module that receives ioeventfd notification.
// linux/drivers/vhost/net.c
static int vhost_net_open(struct inode *inode, struct file *f) {
...
n->vqs[VHOST_NET_VQ_TX].vq.handle_kick = handle_tx_kick;
n->vqs[VHOST_NET_VQ_RX].vq.handle_kick = handle_rx_kick;
...
}
void vhost_dev_init(...) {
...
for (i = 0; i < dev->nvqs; ++i) {
vhost_vq_reset(dev, vq);
if (vq->handle_kick) {
vhost_poll_init(&vq->poll, vq->handle_kick, EPOLLIN, dev);
}
}
}
/* Init poll structure */
void vhost_poll_init(struct vhost_poll *poll, vhost_work_fn_t *fn,
__poll_t mask, struct vhost_dev *dev) {
init_waitqueue_func_entry(&poll->wait, vhost_poll_wakeup);
init_poll_funcptr(&poll->table, vhost_poll_func);
vhost_work_init(&poll->work, fn); // kernel worker polls, and execute the given function when it receives an event.
}
where the given function to be called handle_tx_kick:
// linux/drivers/vhost/net.c
handle_tx_kick()
handle_tx()
handle_tx_copy()
static void handle_tx_copy(struct vhost_net *net, struct socket *sock) {
...
do {
head = get_tx_bufs(net, nvq, &msg, &out, &in, &len, &busyloop_intr);
/* On Error, stop handling until the next kick. */
if (unlikely(head < 0))
break;
/* Nothing new? Wait for eventfd to tell us they refilled. */
if (head == vq->num) {
vhost_enable_notify(&net->dev, vq);
}
/* For simplicity, TX batching is only enabled if
* sndbuf is unlimited.
*/
if (sock_can_batch) {
vhost_net_build_xdp(nvq, &msg.msg_iter);
/* if no error */ goto done;
}
/* If we can't build XDP buff */
...
sock->ops->sendmsg(sock, &msg, len);
done:
vq->heads[nvq->done_idx].id = cpu_to_vhost32(vq, head);
vq->heads[nvq->done_idx].len = 0;
} while(likely(!vhost_exceeds_weight(vq, ++send_pkts, total_len)));
vhost_tx_batch(net, nvq, sock, &msg);
}
Note that XDP (eXpress Data Path) is out of context of this post. Please refer to the Red Hat blog for introduction.
XDP is supported by Linux since version 4.8: For older version of Linux kernel, it just uses sock->ops->sendmsg().
But the kernel community never sleeps and the holy grail of kernel-based networking performance has been found under the name of XDP: the eXpress Data Path. This technology allows you to implement net networking features via custom extended BFS (eBPF) programs attached to the kernel packet processing deep down the stack, killing the overhead of socket buffers (SKBs) management, reducing the per-packet memory management overhead, and allowing more-effective bulking.
After handling the I/O requests, vhost sends a signal to the guest with irqfd (or eventfd in the comment?):
// linux/drivers/vhost/vhost.c
/* This actually signals the guest, using eventfd */
void vhost_signal(struct vhost_dev *dev, struct vhost_virtqueue *vq) {
/* Signal the Guest tell them we used something up. */
if (vq->call_ctx.ctx && vhost_notify(dev, vq))
eventfd_signal(vq->call_ctx.ctx, 1);
}
/* And here's the combo meal deal. Supersize me! */
void vhost_add_used_and_signal(struct vhost_dev *dev,
struct vhost_virtqueue *vq,
unsigned int head, int len) {
vhost_add_used(vq, head, len);
vhost_signal(dev, vq);
}
// linux/drivers/vhost/net.c
vhost_tx_batch()
vhost_net_signal_used()
vhost_add_used_add_signal_n()
vhost_add_used_and_signal()
where vhost_tx_batch() is called by handle_tx_copy() described above.
Summary #
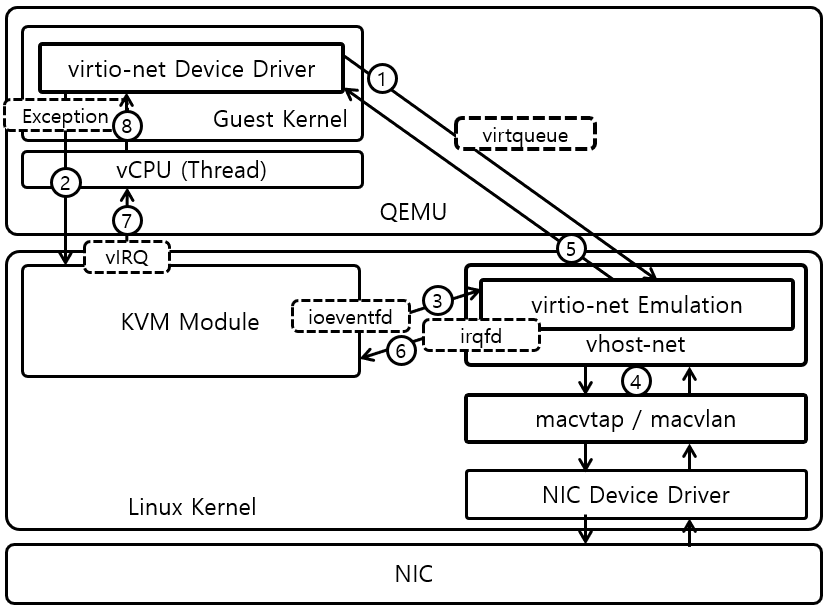
- vhost implements vhost kernel module, and moves I/O request handling job from QEMU process to kernel module to reduce the overall number of context switches.
- virtqueue is created by the guest operating system, which is registered by QEMU to vhost kernel module; hence virtqueue is shared by the guest operating system and the host operating system.
- When virtio front-end device driver inserts I/O requests into the virtqueue and kicks, the vhost kernel module receives the I/O requests. Instead of forwarding the execution context to QEMU, the vhost kernel module directly handles the submitted I/O requests using underlying network/block devices (1, 2, 3?, 4).
- When vhost kernel module finishes its execution, it signals to the guest operating system that the operation is done via ioeventfd (in illustration, was irqfd). And then, KVM resumes guest execution, and the virtio front-end device driver running in the guest operating system receives the result from the virtqueue (6?, 7, 8, 5).