Virtio and Vhost Architecture - Part 1
Table of Contents
This post explains virtio and vhost, device virtualization techniques used in Linux kernel virtual machine (KVM). Here, I focus only on block device and network device virtualization.
Virtio (Virtual I/O) #
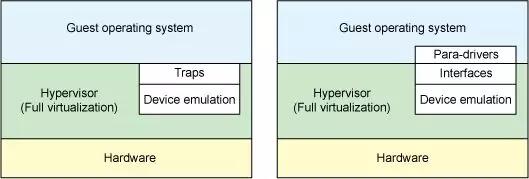
Virtio is one of I/O (block, NIC, etc) virtualization techniques that are used in virtualization. It is a paravirtualized I/O solution that implements a set of communication framework for I/O interaction between guest applications and hypervisor 1 2, which means a device driver that is aware of virtualization is required. Compared to full-virtualized devices which uses trap for actual I/O operations, paravirtualized devices can reduce a lot of wasted cycles with direct communication between guest and host, hence it is faster.
// Kernels device communication with VMware (emulated, full-virtualization):
void nic_write_buffer(char *buf, int size) {
for (; size > 0; size--) {
nic_poll_ready(); // many traps
outb(NIC_TX_BUF, *buf++); // many traps
}
}
// Kernels device communication with hypervisor (hypercall, para-virtualization):
void nic_write_buffer(char *buf, int size) {
vmm_write(NIC_TX_BUF, buf, size); // one trap
}
Architecture 2 3 4 #
virtio can be divided into several parts: front-end drivers (para-drives in the figure) and back-end drivers (interfaces in the figure).
- Front-end virtio drivers: implemented in the guest operating system as a device driver.
- Back-end virtio drivers: implented in the hypervisor. It accepts I/O requests from a front-end driver and perform the corresponding I/O operations via a physical device.
- Transport: Communication between front-end drivers and back-end drivers is done through a queue called virtqueue (or transport, vring, virtio-ring, etc).
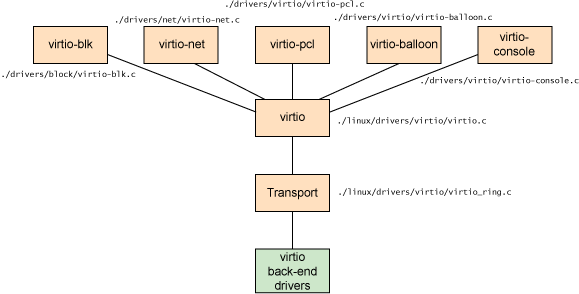
Front-end virtio #
Orange blocks in the above figure are in front-end virtio.
At the top of the architecture is five types of virtio_driver, which represents the front-end driver in the guest operating system.
Devices are encapsulated by the virtio_device, which refers to virtqueue objects that will be used for communication with virtio back-end drivers 2.
Those three data structures are defined in linux/include/linux/virtio.h.
// linux/include/linux/virtio.h
/* virtqueue - a queue to register buffers for sending or receiving. */
struct virtqueue {
struct list_head list;
void (*callback)(struct virtqueue *vq);
const char *name;
struct virtio_device *vdev;
unsigned int index;
unsigned int num_free;
void *priv;
};
/* virtio_device - representation of a device using virtio */
struct virtio_device {
int index;
bool failed;
bool config_enabled;
bool config_change_pending;
spinlock_t config_lock;
struct device dev;
struct virtio_device_id id;
const struct virtio_config_ops *config;
const struct vringh_config_ops *vringh_config;
struct list_head vqs;
u64 features;
void *priv;
};
/* virtio_driver - operations for a virtio I/O driver */
struct virtio_driver {
struct device_driver driver;
const struct virtio_device_id *id_table;
const unsigned int *feature_table;
unsigned int feature_table_size;
const unsigned int *feature_table_legacy;
unsigned int feature_table_size_legacy;
int (*validate)(struct virtio_device *dev);
int (*probe)(struct virtio_device *dev);
void (*scan)(struct virtio_device *dev);
void (*remove)(struct virtio_device *dev);
void (*config_changed)(struct virtio_device *dev);
#ifdef CONFIG_PM
int (*freeze)(struct virtio_device *dev);
int (*restore)(struct virtio_device *dev);
#endif
};
While IBM article describes relationships between those data structures, it has been deprecated since Linux 2.6.35 and there is no longer virtqueue_ops data structure.
Before Linux 2.6.35, it had been used like:
/* DEPRECATED AND NO LONGER EXISTS IN MODERN LINUX. FOR REFERENCE ONLY */
// linux/include/linux/virtio.h
/**
* @add_buf: expose buffer to other end
* @kick: update after add_buf
* @get_buf: get the next used buffer
* @disable_cb: disable callbacks
* @enable_cb: restart callbacks after disable_cb
*/
struct virtqueue_ops {
int (*add_buf)(struct virtqueue *vq,
struct scatterlist sg[],
unsigned int out_num,
unsigned int in_num,
void *data);
void (*kick)(struct virtqueue *vq);
void *(*get_buf)(struct virtqueue *vq, unsigned int *len);
void (*disable_cb)(struct virtqueue *vq);
bool (*enable_cb)(struct virtqueue *vq);
};
// linux/drivers/virtio/virtio_ring.c
static struct virtqueue_ops vring_vq_ops = {
.add_buf = vring_add_buf, // <--
.get_buf = vring_get_buf,
.kick = vring_kick,
.disable_cb = vring_disable_cb,
.enable_cb = vring_enable_cb,
};
struct virtqueue *vring_new_virtqueue(...) {
struct vring_virtqueue *vq;
vq = kmalloc(sizeof(*vq) + sizeof(void*)*num, GFP_KERNEL);
...
vq->vq.vq_ops = &vring_vq_ops;
...
return &vq->vq;
}
// linux/drivers/block/virtio_blk.c
static bool do_req(struct request_queue *q,
struct virtio_blk *vblk,
struct request *req) {
...
vblk->vq->vq_ops->add_buf(vblk->vq, vblk->sg, out, in, vbr);
...
return true;
}
static void do_virtblk_request(struct request_queue *q) {
...
do_req(q, vblk, req);
...
vblk->vq->vq_ops->kick(vblk->vq);
}
static int __devinit virtblk_probe(struct virtio_device *vdev) {
...
// omitted definition of blk_init_queue (in linux/block/blk-core.c).
// Call the function pointer given as the first function argument for each queue entry.
vblk->dist->queue = blk_init_queue(do_virtblk_request, &vblk->lock);
...
}
statis struct virtio_driver __refdata virtio_blk = {
...
.probe = virtblk_probe,
};
Now without virtqueue_ops, a virtio block device uses virtqueue as:
// linux/drivers/virtio/virtio_ring.c
/* virtqueue_add_sgs - expose buffers to other end (equivalent to virtqueue_ops::add_buf) */
int virtqueue_add_sgs(struct virtqueue *_vq,
struct scatterlist *sgs[],
unsigned int out_sgs,
unsigned int in_sgs,
void *data,
gfp_t gfp) {
...
}
// linux/drivers/block/virtio_blk.c
static int virtblk_add_req(struct virtqueue *vq,
struct virtblk_req *vbr,
struct scatterlist *data_sg,
bool have_data) {
...
return virtqueue_add_sgs(vq, sgs, num_out, num_in, vgr, GFP_ATOMIC);
}
static blk_status_t virtio_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd) {
struct request *req = bd->rq;
...
virtblk_add_req(vblk->vgs[qid].vq, vbr, vbr->sg, num);
...
virtqueue_kick_prepare(vblk->vgs[qid].vq);
virtqueue_notify(vblk->vqs[qid].vq);
return BLK_STS_OK;
}
static const struct blk_mq_ops virtio_mq_ops = {
.queue_rq = virtio_queue_rq, // <--
.commit_rqs = virtio_commit_rqs,
.complete = virtblk_request_done,
.init_request = virtblk_init_request,
#ifdef CONFIG_VIRTIO_BLK_SCSI
.initialize_rq_fn = virtblk_initialize_rq,
#endif
.map_queues = virtblk_map_queues,
};
static int virtblk_probe(struct virtio_device *vdev) {
...
vblk->tag_set.ops = &virtio_mq_ops;
...
}
static struct virtio_driver virtio_blk = {
...
.probe = virtblk_probe,
...
};
I/O Request Processing Flow (front-end) 3 #
I/O data flow is well illustrated in 11~15 pages of 5, while it is also obsolete and should be refined. To be summarized:
virtio_driverin the guest operating system callsvirtblk_add_req(), which callsvirtqueue_add_sgs()(wasvirtqueue_ops::add_buf()).virtio_driverin the guest operating system callsvirtqueue_kick_prepare()andvirtqueue_notify()invirtio_queue_rqfunctions (wasvirtqueue_ops::kick()). Note that two functions should be called for a kick.
// linux/drivers/virtio/virtio_ring.c
/**
* Instead of virtqueue_kick(), you can do:
* if (virtqueue_kick_prepare(vq))
* virtqueue_notify(vq);
*/
// virtqueue_kick_prepare - first half of split virtqueue_kick call.
bool virtqueue_kick_prepare(struct virtqueue *_vq);
// virtqueue_notify - second half of split virtqueue_kick call.
bool virtqueue_notify(struct virtqueue *_vq);
- Then the back-end device driver will pop the request, handle it, and push result into
outbuffer (will be explained later, as it is not a part of front-end). - When context returns to the guest operating system,
virtblk_doneofvirtio_driveris called, which callsvirtqueue_get_buf()(wasvirtqueue_ops::get_buf()).
Kick Internal #
// linux/drivers/virtio/virtio_ring.c
bool virtqueue_notify(struct virtqueue *_vq) {
struct vring_virtqueue *vq = to_vvq(_vq);
/* Prod other side to tell it about changes. */
vq->notify(_vq); // omitted exception handling code
return true;
}
where vq->notify() is defined as:
// called by vring_new_virtqueue() and vring_create_virtqueue_split().
struct virtqueue *__vring_new_virtqueue(...,
bool (*notify)(struct virtqueue *),
void (*callback)(struct virtqueue *)) {
...
vq->notify = notify;
}
struct virtqueue *vring_create_virtqueue
unsigned int index,
unsigned int num,
unsigned int vring_align,
struct virtio_Device *vdev,
bool weak_barriers,
bool may_reduce_num,
bool context,
bool (*notify)(struct virtqueue *),
bool (*callback)(struct virtqueue *),
const char *name) {
...
return vring_create_virtqueue_split(...);
}
// linux/drivers/virtio/virtio_pci_modern.c
static struct virtqueue *setup_vq(struct virtio_pci_device *vp_dev,
struct virtio_pci_vq_info *info,
unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec) {
...
struct virtqueue *vq = vring_create_virtqueue(index, num,
SMP_CACHE_BYTES, &vp_dev->vdev,
true, true, ctx,
vp_notify, callback, name);
}
// linux/drivers/virtio/virtio_pci_common.c
/* the notify function used when creating a virt queue */
bool vp_notify(struct virtqueue *vq) {
/* we write the queue's selector into the notification register to
* the signal the other end */
iowrite16(vq->index, (void __iomem *)vq->priv);
return true;
}
Note that writing a value into the virtio device’s register incurs a VMexit:
It (a virtqueue) driver to device notifications (doorbell) method, to signal that one or more buffers have been added to the queue, and vice-versa, devices can interrupt the driver to signal used buffers. It is up to the underlying driver to provide the right method to dispatch the actual notification, for example using PCI interruptions or memory writing: The virtqueue only standardizes the semantics of it. [Source]
For special memory regions, KVM follows a similar approach, marking memory regions as Read Only or not mapping them at all, causing a vmexit with the KVM_EXIT_MMIO reason. [Source]
Guest->QEMU context transition: Whenever guest context incurs a vmexit, the CPU will exit to kernel mode KVM handlers first. Then, the KVM module will determine if this particular vmexit should be handled by userspace (not that kernel KVM module will handle some particular vmexit itself rather than exposing to userspace). If so, the
ioctl()syscall that caused the QEMU->Guest transition will return to userspace, and then we will be back at QEMU context. [Source]QEMU->Guest context transition: Similarly, the device notifications are a special ioctl the host can send to the KVM device (vCPU IRQ). [Source]
Virtqueue Internal 6 #
A virtqueue consists of three parts:
- descriptor area: used for describing buffers. Implemented as
vring_descdata structure. - driver area: data supplied by front-end driver to the back-end device. Also called avail virtqueue. Implemented as
vring_availdata structure. - device area: data supplied by back-end device. Also called used virtqueue. Implemented as
vring_useddata structure.
linux/include/uapi/linux/virtio_ring.h
/* Virtio ring descriptors: 16 bytes. These can chain together via "next". */
struct vring_desc {
__virtio64 addr; /* Address (guest-physical). */
__virtio32 len; /* Length. */
__virtio16 flags; /* The flags as indicated above. */
__virtio16 next; /* We chain unused descriptors via this, too */
};
struct vring_avail {
__virtio16 flags;
__virtio16 idx;
__virtio16 ring[];
};
struct vring_used_elem {
__virtio32 id; /* Index of start of used descriptor chain. */
__virtio32 len; /* Total length of the descriptor chain which was used (written to) */
};
typedef struct vring_used_elem __attribute__((aligned(VRING_USED_ALIGN_SIZE)))
vring_used_elem_t;
struct vring_used {
__virtio16 flags;
__virtio16 idx;
vring_used_elem_t ring[];
}
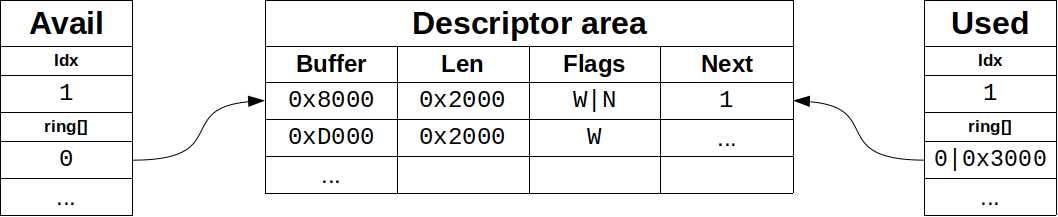
Since a virtqueue can be separated into those three areas, we call it as a split virtqueue.
There is another type of virtqueue that can be inferred from here:
virtqueue_packed. For more information regarding this, refer to this post.
Back-end virtio #
According to 7, when a client (the guest) writes data to the address, it will trigger a VM-exit with reason EPT_MICONFIGURATION page fault abnormality, forwarding the execution context from the guest operating system to KVM VM-exit handler.
If the KVM finds that this address falls within the registered ioeventfd address range, it will notify QEMU by writing the associated eventfd.
vp_notify() is called by virtio front-end device driver in the guest operating system, an interrupt occurs and the execution context has been forwarded from the guest operating system to QEMU userspace process via ioeventfd 7.
QEMU uses kvm_set_ioeventfd_mmio() and kvm_set_ioeventfd_pio() functions to register ioeventfds to KVM with specific address, then later KVM will forward the execution context when the guest writes this address space.
# qemu/hw/accel/kvm-all.c
static int kvm_set_ioeventfd_mmio(int fd, hwaddr addr, uint32_t val,
bool assign, uint32_t size, bool datamatch) {
struct kvm_ioeventfd iofd = {
.datamatch = datamatch ? adjust_ioeventfd_endianness(val, size) : 0;
.addr = addr,
.len = size,
.flags = 0,
.fd = fd,
};
kvm_vm_ioctl(kvm_state, KVM_IOEVENTFD, &iofd);
}
static void kvm_mem_ioeventfd_add(MemoryListener *listener,
MemoryRegionSection *section,
bool match_data, uint64_t data,
EventNotifier *e) {
int fd = event_notifier_get_fd(e);
kvm_set_ioeventfd_mmio(fd, section->offset_within_address_space,
data, true, int128_get64(section->size), match_data);
...
}
static int kvm_init(MachineState *ms) {
...
if (kvm_eventfds_allowed) {
s->memory_listener.listener.eventfd_add = kvm_mem_ioeventfd_add;
s->memory_listener.listener.eventfd_del = kvm_mem_ioeventfd_del;
}
memory_listener_register(&kvm_io_listener, &address_space_io);
memory_listener_register(&kvm_coalesced_pio_listener, &address_space_io);
...
}
where I guess ioeventfd comes from virtio area:
// qemu/hw/virtio/virtio-bus.c
/*
* This function switches ioeventfd on/off in the device.
* The caller must set or clear the handlers for the EventNotifier.
*/
int virtio_bus_set_host_notifier(VirtioBusState *bus, int n, bool assign) {
VirtioBusClass *k = VIRTIO_BUS_GET_CLASS(bus);
DeviceState *proxy = DEVICE(BUS(bus)->parent);
VirtIODevice *vdev = virtio_bus_get_device(bus);
VirtQueue *vq = virtio_get_queue(vdev, n);
EventNotifier *notifier = virtio_queue_get_host_notifier(vq);
r = event_notifier_init(notifier, 1);
k->ioeventfd_assign(proxy, notifier, n, true);
virtio_queue_set_host_notifier_enabled(vq, assign);
...
}
// qemu/hw/virtio/virtio-pci.c
static int virtio_pci_ioeventfd_assign(DeviceState *d, EventNotifier *notifier,
int n, bool assign) {
VirtIOPCIProxy *proxy = to_virtio_pci_proxy(d);
VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus);
VirtQueue *vq = virtio_get_queue(vdev, n);
MemoryRegion *modern_mr = &proxy->notify.mr;
hwaddr modern_addr = virtio_pci_queue_mem_multi(proxy) *
virtio_get_queue_index(vq);
memory_region_add_eventfd(modern_mr, modern_addr, 0,
false, n, notifier);
...
}
// qemu/softmmu/memory.c
void memory_region_add_eventfd(MemoryRegion *mr,
hwaddr addr,
unsigned size,
bool match_data,
uint64_t data,
EventNotifier *e) {
MemoryRegionIoeventfd mrfd = {
.addr.start = int128_make64(addr),
.addr.size = int128_make64(size),
.match_data = match_data,
.data = data,
.e = e,
};
memory_region_transaction_begin();
memory_region_ioeventfd_before(&mrfd, &mr->ioeventfds[i]);
++mr->ioeventfd_nb;
mr->ioeventfds = g_realloc(mr->ioeventfds, sizeof(*mr->ioeventfds) * mr->ioeventfd_nb);
memmove(&mr->ioeventfds[i+1], &mr->ioeventfds[i], sizeof(*mr->ioeventfds) * (mr->ioeventfd_nb-1 -i));
mr->ioeventfds[i] = mrfd;
memory_region_transaction_commit();
}
void memory_region_transaction_commit(void) {
AddressSpace *as;
...
QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) {
address_space_update_ioeventfd(as);
}
}
static void address_space_update_ioeventfds(AddressSpace *as) {
...
address_space_add_del_ioeventfds(as, ioeventfds, ioeventfd_nb,
as->ioeventfds, as->ioeventfd_nb);
}
static void address_space_add_del_ioeventfds(AddressSpace *as,
MemoryRegionIoeventfd *fds_new,
unsigned fds_new_nb,
MemoryRegionIoeventfd *fds_old,
unsigned fds_old_nb) {
...
MEMORY_LISTENER_CALL(as, eventfd_add, Reverse, §ion, fd->match_data, fd->data, fd->e);
}
where MEMORY_LISTENER_CALL seems to call the registered eventfd add memory listener kvm_mem_ioeventfd_add().
Once finished reading/writing operations, QEMU injects an IRQ to notify that the operation is complete.
// qemu/hw/virtio.c
void virtio_notify_irqfd(VirtIODevice *vdev, VirtQueue *vq) {
...
virtio_set_isr(vq->vdev, 0x1);
event_notifier_set(&vq->guest_notifier);
}
// qemu/hw/block/dataplane/virtio-blk.c
void virtio_blk_data_plane_notify(VirtIOBlockDataPlane *s, VirtQueue *vq) {
virtio_notify_irqfd(s->vdev, vq);
}
// qemu/hw/block/virtio-blk.c
static void virtio_blk_req_complete(VirtIOBlockReq *req, unsigned char status) {
...
if (s->dataplane_started && !s->dataplane_disabled) {
virtio_blk_data_plane_notify(s->dataplane, req->vq);
} else {
virtio_notify(vdev, req->vq);
}
}
static void virtio_blk_rw_complete(void *opaque, int ret) {
VirtIOBlockReq *next = opaque;
...
virtio_blk_req_complete(req, VIRTIO_BLK_S_OK);
...
}
Summary 8 #
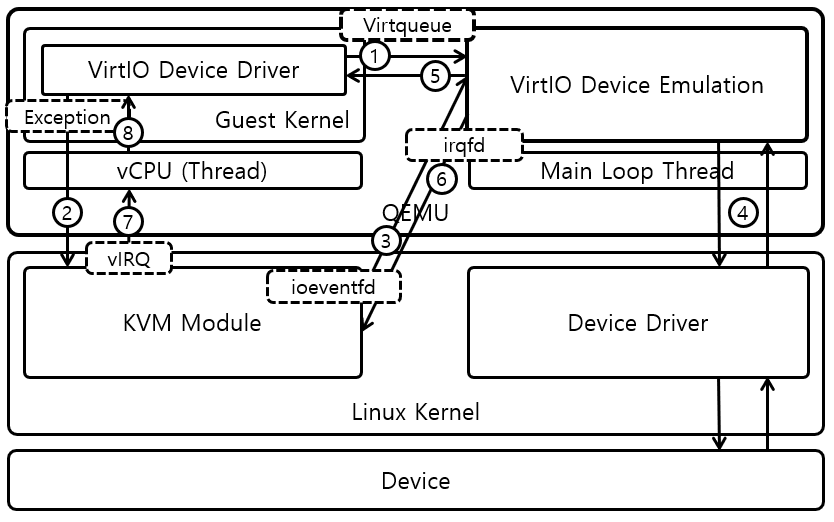
- VirtI/O is implemented with virtqueues, shared by the guest and QEMU process.
- When the guest rings a doorbell after inserting requests into the virtqueue, the context is forwarded to host KVM handler (VM-exit), and again to QEMU process via ioeventfd (1, 2, 3).
- QEMU process reads the request from the shared virtqueue, and handles it. After completion, QEMU puts the result into the virtqueue and injects an IRQ through irqfd to the guest (4, 5, 6).
- When the guest execution is resumed, the request I/O operation is done and virtio device driver gets result data from the virtqueue (7, 8, 5).
The next part explains overheads of virtio, and introduce vhost that can increase performance of virtio.
-
Virtualization technology implementation - KVM I/O virtualization ↩︎
-
IBM Developer: Virtio: An I/O Virtualization Framework for Linux ↩︎ ↩︎ ↩︎
-
ProgrammerSought: IO Virtualization - virtio-blk front-end Driver Analysis ↩︎ ↩︎
-
ProgrammerSought: IO Virtualization - virtio Introduction and Code Analysis ↩︎
-
CMU Lecture Slide: Virtio: An I/O Virtualization Framework for Linux ↩︎
-
Red Hat Blog: Virtqueues and Virtio Ring: How the Data Travles ↩︎