Using Ceph RBD as a QEMU Storage
Table of Contents
This post explains how we can use a Ceph RBD as a QEMU storage.
We can attach a Ceph RBD to a QEMU VM through either virtio-blk or vhost-user-blk QEMU device (vhost requires SPDK).
Assume that a Ceph cluster is ready following the manual.
Setting a Ceph client Configuration 1 #
For a node to access a Ceph cluster, it requires some configuration:
- Config file setup
- User authentication setup
This step requires an access permission to a host; a host refers to a node that is already configured as a client or running a cluster daemon.
Install Ceph client package #
All you need to install for a client node is ceph-common:
$ apt install ceph-common
Config file setup #
Run the following command in the host:
$ ceph config generate-minimal-conf
# minimal ceph.conf for <fsid>
[global]
fsid = <fsid>
mon_host = [v2:.../0,v1:.../0]
Copy the 4 lines and paste it into /etc/ceph/ceph.conf on the client node:
# on the client node
$ cat /etc/ceph/ceph.conf
[global]
fsid = <fsid>
mon_host = [v2:.../0,v1:.../0]
Keyring setup #
Most Ceph clusters are run with authentication enabled, and the client will need keys in order to communicate with cluster machines.
For better security, we could create a new user with less privilege and use this credential, following this manual 2. This post just uses the admin user to access the cluster for simplicity:
# on the host node
$ ceph auth get client.admin &> ceph.client.admin.keyring
# copy ceph.client.admin.keyring file to /etc/ceph of the client node...
The file should be located /etc/ceph/ceph.client.admin.keyring, or /etc/ceph/ceph.client.<username>.keyring, if you created a new user. ceph automatically searches keyrings in /etc/ceph directory.
You can see all authentication keyrings by using
ceph auth lscommand.Do not use
adminkeyring in public clusters.
From here, Ceph hosts are no longer required. All commands are executed in a Ceph client node.
Creating a RBD #
Creating a Pool 3 #
To create a RBD, you first need to create a pool, as all RBDs should be assigned into a pool. Follow 4 and 3 to create a pool and a RBD:
$ ceph osd pool create testpool
pool 'testpool' created
Just in case… you need to set
mon_allow_pool_deleteconfig option to true to delete a pool, with the following commands 5:ceph tell mon.* injectargs --mon_allow_pool_delete trueIt was supposed to reload monitor daemons after adding the configuration
mon_allow_pool_deletein/etc/ceph/ceph.confconfiguration file, but thisinjectargssubcommand enables runtime argument injection.
Then, use the rbd tool to initialize the pool for use by RBD 4:
$ rbd pool init <pool-name>
This makes the given pool usable by RBD. To check it, type:
$ ceph osd pool ls detail
...
pool 2 'rbd' replicated ... application rbd # <-- this pool is for rbd
Creating a RBD 4 6 #
Now create a RBD with the following command:
$ rbd create --size <megabytes> <pool-name>/<image-name>
For example, rbd create --size 2048 testpool/testimage creates a 2GB block device image named testimage in testpool pool.
You can get information of the create image via:
rbd ls: list all images. If want to list images in a specific pool, append the poolname.rbd info <image-name>: retrieve image information:rbd info testimage rbd image 'testimage': size 16 MiB in 4 objects order 22 (4 MiB objects) snapshot_count: 0 id: 8635aeee3f08 block_name_prefix: rbd_data.8635aeee3f08 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Thu Mar 4 16:09:01 2021 access_timestamp: Thu Mar 4 16:09:01 2021 modify_timestamp: Thu Mar 4 16:09:01 2021
Using Ceph RBD for QEMU VM Storage (virtio) #
Now a Ceph RBD image is ready. You can use this image as a storage backend of a QEMU VM.
You can use krbd kernel module or librbd userspace library to use the RBD image.
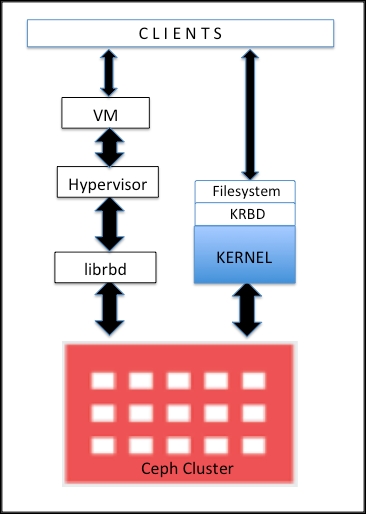
Using krbd kernel module #
Following this step, map the image to a block device:
rbd map <image-name> [--name <client.admin>] [-m <mon-ip>] [-k /path/to/ceph.client.admin.keyring] [-p <pool-name>]
All arguments except image-name are optional. if IP addresses of monitors are not given, rbd infers it using /etc/ceph/ceph.conf (in the previous setup, we configured /etc/ceph/ceph.conf with mon_host value). The default value of pool-name is rbd.
For example, if you created a RBD image via rbd create --size ... testpool/testimage, you can map the image via rbd map testimage -p testpool.
$ rbd map testimage -p testpool
/dev/rbd0
Now you can access the image via /dev/rbd0 device.
$ qemu-system-x86_64 ... \
-drive format=raw,id=rbd1,file=/dev/rbd0,if=none \
-device virtio-blk-pci,driver=rbd1,id=virtioblk0
Using librbd library #
According to 7, there is no need to map an image as a block device on the host (here, the host means the host kernel from the view of virtual machines, not the Ceph host) since QEMU 0.15, and it attaches an image as a virtual block device directly via librbd.
Without doubt, it could increase performance as I/O path does not include krbd kernel module, thus reducing context switches.
$ qemu-system-x86_64 ... \
-drive format=rbd,id=rbd1,file=rbd:<pool-name>/<image-name>,if=none \
-device virtio-blk-pci,drive=rbd1,id=virtioblk0
Using Ceph RBD for QEMU VM Storage (SPDK vhost) #
Building SPDK #
This requires SPDK.
SPDK manual is well maintained and following it would be enough 8:
$ git clone https://github.com/spdk/spdk
$ cd spdk; git submodule update --init
$ ./scripts/pkgdep.sh --all
$ apt install librados-dev librbd-dev /* or */ dnf install librados2-devel librbd-devel
$ ./configure --with-rbd
$ make
SPDK applications including vhost requires hugepages:
$ HUGEMEM=4096 ./scripts/setup.sh
vhost requires at least 4GB (
HUGEMEM=4096) of hugepages.
This setup script is for allocating hugepages and binding vfio-pci/uio_pci_generic kernel module to NVMe devices, however, I use this script only for hugepages allocation.
If you are using any NVMe devices, use PCI_BLOCKED argument not to bind vfio-pci/uio_pci_generic to those devices. setup.sh help explains how to use the argument very well.
SPDK Configuration #
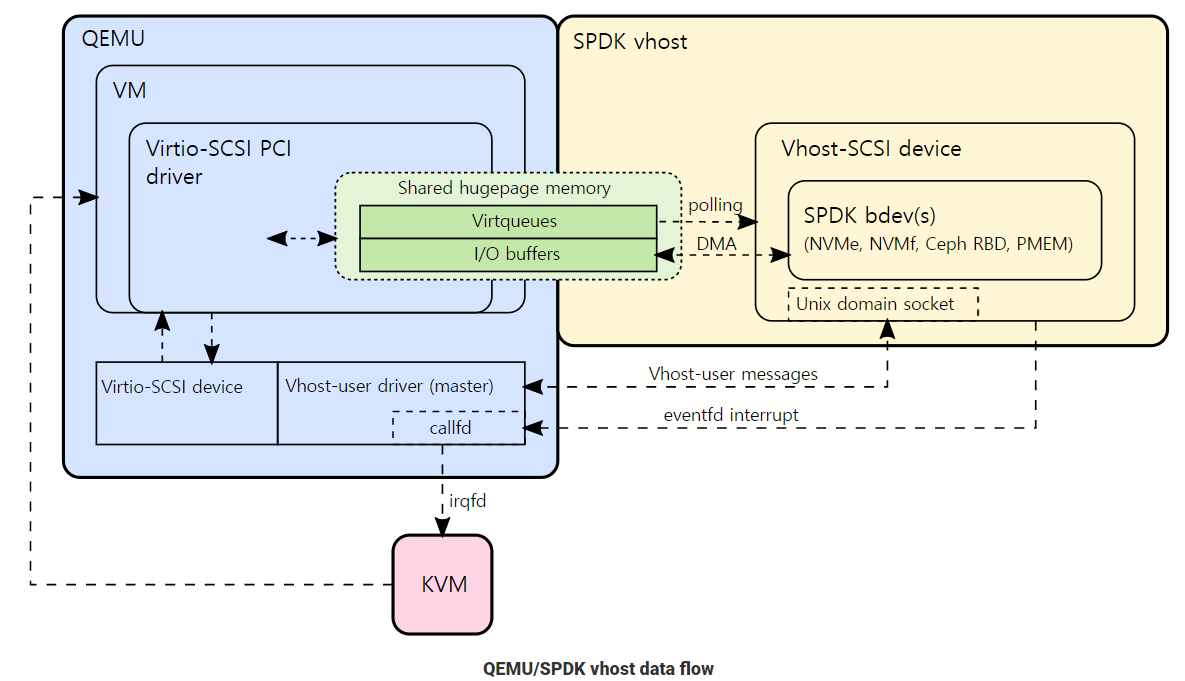
SPDK vhost process is a local storage service as a process running on the host OS. As the vhost process serves a storage service to VMs, the host kernel is no longer involved in the entire I/O process.
For Ceph RBD backend, SPDK vhost uses librbd to access bdev.
For a VM to work, the following components need to be created:
- SPDK vhost process
- SPDK bdev (Ceph RBD backend)
vhost-scsiorvhost-user-blkcontroller
Starting SPDK vhost target process #
$ ./build/bin/vhost -S /var/tmp -m 0x3
The above command will start vhost on CPU cores 0 and 1 (cpumask 0x3) with all future socket files placed in /var/tmp.
vhostwill fully occupy given CPU cores for I/O polling 9.
cpumask 0x3 means b0011, which means two vhost reactor threads run on core 0 and 1, respectively; if you want to use more cores for vhost or modify core target, we should use cpumask properly. For example:
- cpumask 0x7:
b0111: use three CPU cores 0, 1, and 2 - cpumask 0x10:
b1010: use two CPU cores 1 and 3
Be aware again that each thread polls and occupies the entire core.
-S specifies a directory that vhost sockets will be created; vhost clients (e.g. QEMU) seem to connect to the vhost process via this socket.
Creating a vhost device with Ceph RBD backend 10 #
Use spdk/scripts/rpc.py and bdev_rbd_create command to create a SPDK RBD bdev: ./scripts/rpc.py bdev_rbd_create <pool-name> <image-name> <block-size>. For example:
$ ./scripts/rpc.py bdev_rbd_create testpool testimage 512
Ceph0
Ceph RBD images are accessed via librbd.
Created bdev CephX is managed by SPDK vhost process as illustrated in vhost data flow, and no block devices in /dev is shown.
Creating a vhost controller and a vhost-blk device for QEMU VMs 11. #
Use spdk/scripts/rpc.py and vhost_create_blk_controller command to create a vhost-blk device that can be used by QEMU (or use vhost_create_scsi_controller command to create vhost-scsi device).
$ ./scripts/rpc.py vhost_create_blk_controller --cpumask 0x1 vhost.1 Ceph0
The RPC command attaches Ceph0 bdev to the vhost.1 vhost-blk controller.
The manual says the above command creates a vhost-blk device exposing Ceph0 device, and the device will be accessible to QEMU via /var/tmp/vhost.1, which means there is still no kernel-level block devices in /dev directory.
Note that --cpumask argument for vhost_create_blk_controller command must be a subset of vhost cpumask: if you run vhost with cpumask 0x3, vhost_create_blk_controller can use cpumask 0x1, 0x2, or 0x3. Otherwise, for example:
# Try to pin a controller to core 2, while vhost is running in core 0 and 1 (cpumask 0x3).
$ ./scripts/rpc.py vhost_create_blk_controller --cpumask 0x4 vhost.1 Ceph0
...
Got JSON-RPC error response
response:
{
"code": -32602,
"message": "Invalid argument"
}
# from stdout of vhost binary
[2021-03-05 10:18:42.774560] bdev_rbd.c: 696:bdev_rbd_create: *ERROR*: Failed to init rbd device
[2021-03-05 10:19:11.943456] bdev_rbd.c: 719:bdev_rbd_create: *NOTICE*: Add Ceph0 rbd disk to lun
[2021-03-05 10:19:34.791038] vhost.c: 913:vhost_parse_core_mask: *ERROR*: one of selected cpu is outside of core mask(=3)
[2021-03-05 10:19:34.791077] vhost.c: 950:vhost_dev_register: *ERROR*: cpumask 0x4 is invalid (core mask is 0x3)
Launching a QEMU VM with SPDK vhost #
Using vhost exposes devices via sockets, not block devices in /dev directory, so QEMU has to access the devices via sockets.
Instead of using -drive argument, we can put a character device indicating the created device socket:
$ qemu-system-x86_64 ... \
-object memory-backend-file,id=mem,size=1G,mem-path=/dev/hugepages,share=on \
-numa node,memdev=mem \
-chardev socket,id=char1,path=/var/tmp/vhost.1 \
-device vhost-user-blk-pci,id=vhostblk0,chardev=char1
I understand that the given memory-backend-file is used for the shared hugepage memory containing virtqueues and I/O buffers, however, I do not understand why it’s size should be same with the entire VM’s memory size and also should be followed by -numa option so far.
# in VM
$ lspci -nnn
00:03.0 SCSI storage controller: Red Hat, Inc. Virtio block device
Subsystem: Red Hat, Inc. Virtio block device
...
$ fdisk -l
...
Disk /dev/vda: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes