Introduction to Ceph
Table of Contents
Ceph is an open-source distributed software platform 1 2. It mainly focuses on scale-out file system including storage distribution and availability.
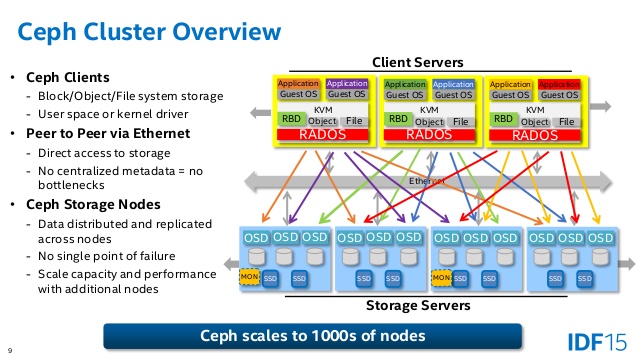
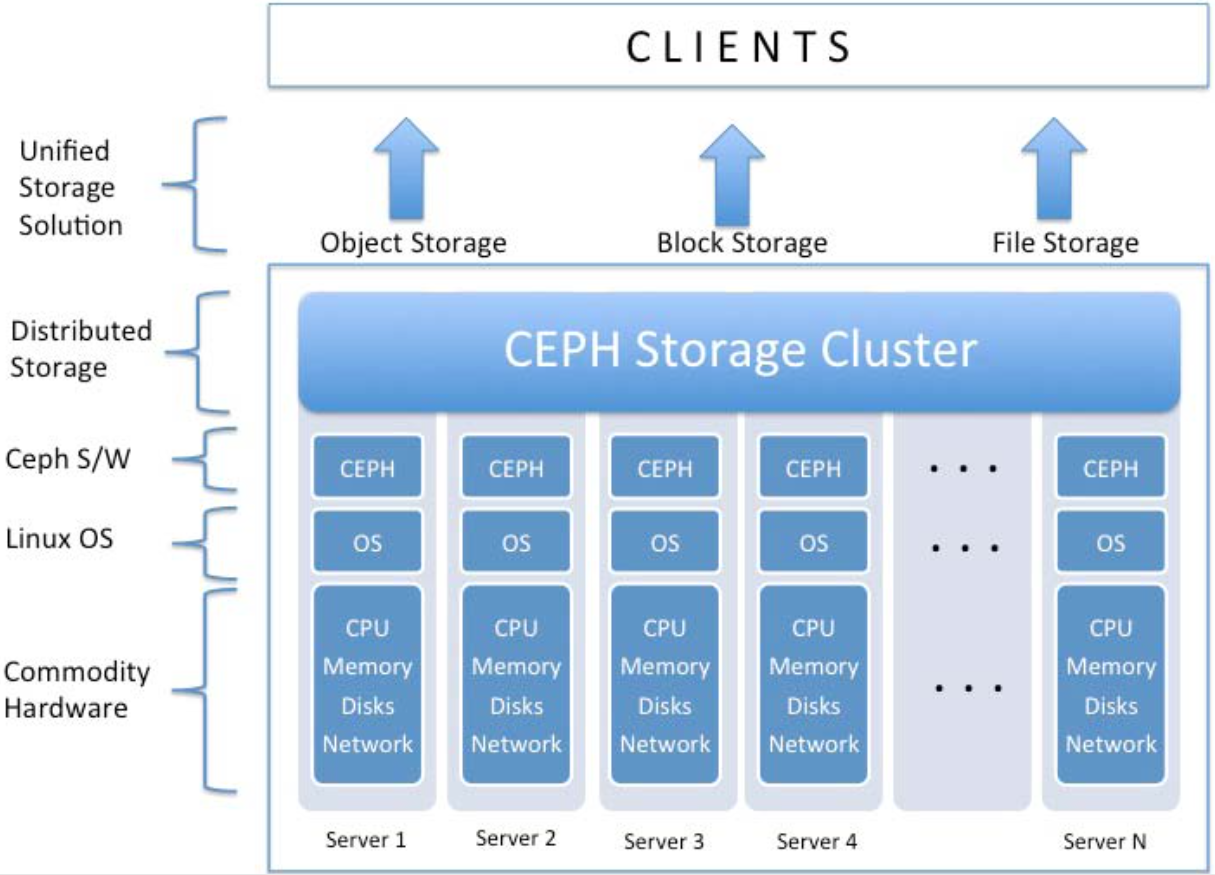
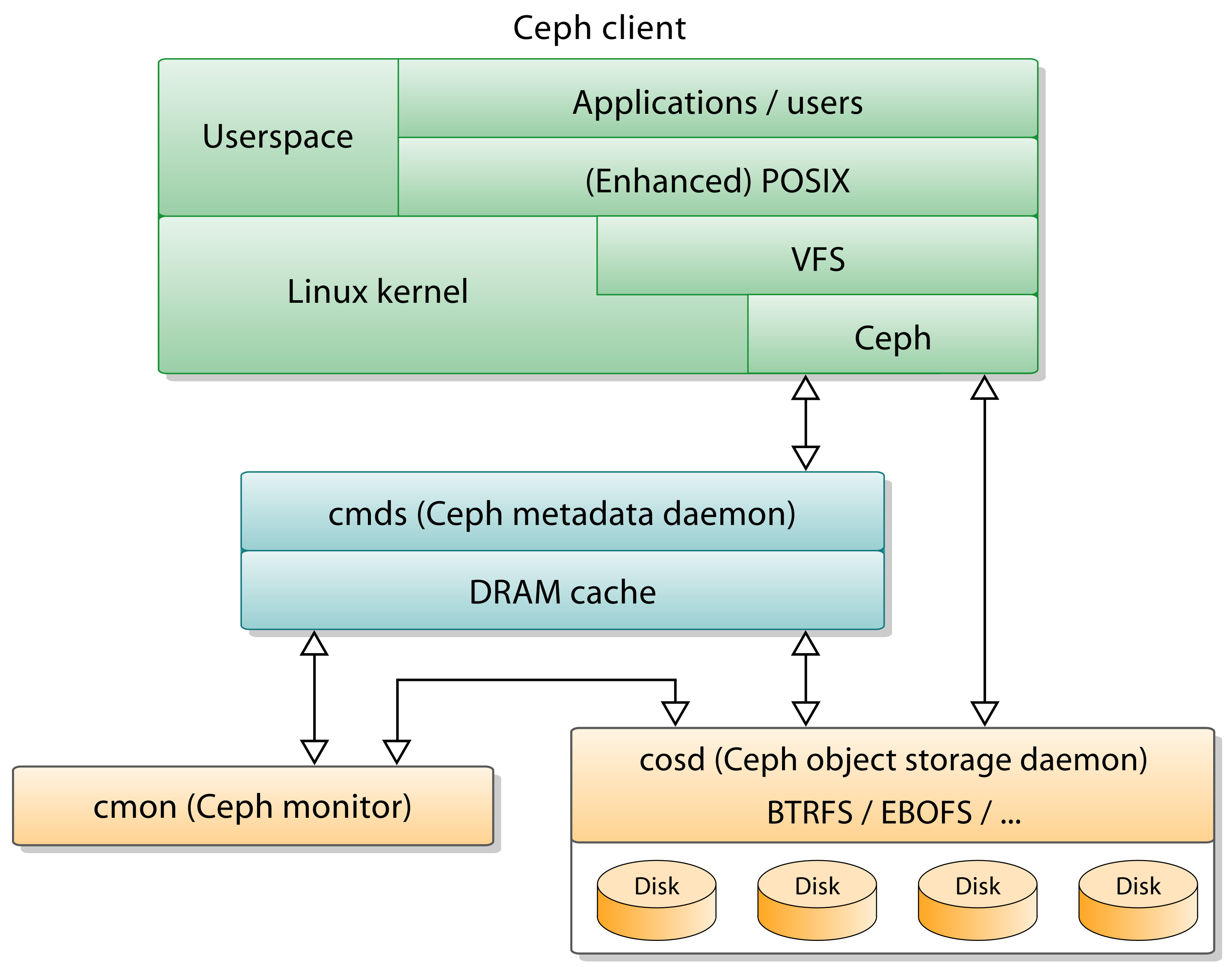
A ceph storage cluster roughly consists of three components:
- Ceph Storage Nodes: equip physical storage media, and Ceph Object Storage Daemons (OSDs, or
ceph-osd), Ceph Monitors (ceph-mon), and Ceph Managers (ceph-mgr) manage them. More details are in Ceph Storage Cluster Architecture section. - Ceph Clients: I at first had no idea what “client servers” in the figure above means; I thought that client servers are a gateway to Ceph storage cluster, but it is not the case. Those are clients and runs parts of Ceph libraries to access the Ceph storage cluster. Ceph provides three interfaces to access the cluster: RADOSGW (object storage), RBD (block storage), and CephFS (file storage). More details are in Ceph Client Architecture section.
- Ceph protocols: communication procotols between the nodes and clients.
1. Ceph Client Architecture #
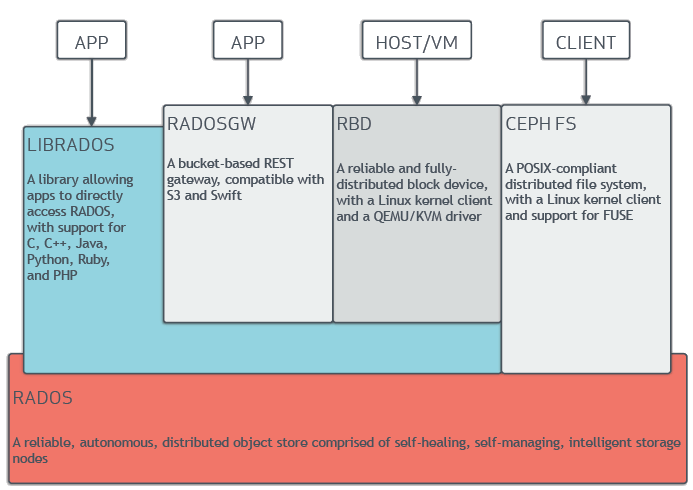
Ceph clients can be categorized into three types (apps, host/VM, and clients), and four ways of accessing a Ceph storage cluster are provided: libRADOS, RADOSGW (object storage), RBD (block storage), or CephFS (file storage).
Object storage vs block storage vs file storage #
I am not clear how to distinguish those terms, so here is my summarized thought and references for understanding.
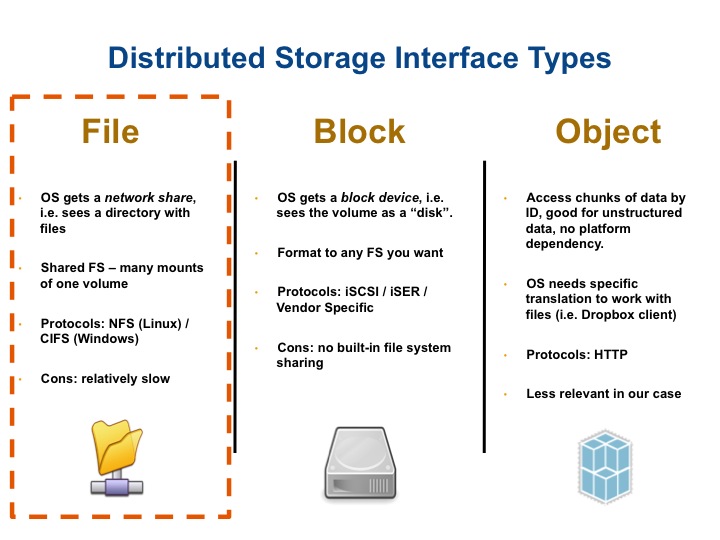
- File storage: clients mount the remote storage through network and access the stored file. The storage is already formatted with proper network file system.
- Block storage: VMs use passthroughed block device and use it. Differently from file storages, it does not need to be formatted with a network file system.
- Object storage: Data are stored as objects. I think inode in ext file system is also one of object types that it refers to, but it seems a difference from file storage is to use network for data query, without kernel’s help for file systems (e.g. VFS).
So three types of accessing methods in Ceph can be explained:
- RADOSGW (RADOS Rest Gateway, or Ceph object gateway) (
src/rgw): it provides a RESTful gateway to Ceph Storage Clusters. it supports two interfaces: Amazon S3 API compatible, or OpenStack Swift API compatible. Clients send a RESTful request (e.g.GET /path/to/object) and RADOSGW will return results will be file objects. - RBD (RADOS Block Device) (
src/rbd_fuse,src/librbd?): it provides a Ceph storage cluster as a block device, so that clients can access the cluster as they access to a/dev/sda*device. - CephFS (
src/libcephfs.cc?): Similarly to the existing file systems, clients can access the cluster through POSIX interface, like they access local file systems (e.g. usingopen()). - libRADOS (
src/librados)
2. Ceph Storage Cluster Architecture #
The nodes are managed by two types of daemons: (1) Ceph Object Storage Daemons (ceph-osd), (2) Ceph Monitors (ceph-mon), and (3) Ceph Managers (ceph-mgr).
Ceph Object Storage Daemons (OSDs) (/src/osd) #
OSDs are reponsible for storing objects on a local file system on behalf of Ceph clients. Also, Ceph OSDs use the CPU, memory, and networking of Ceph cluster nodes for data replication, erasure coding, recovery, monitoring and reporting functions 3.
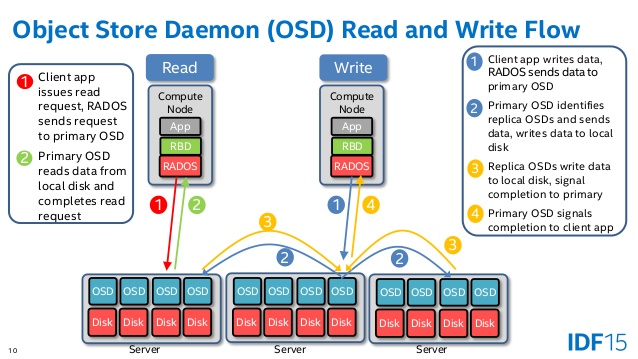
Hence is main responsibility is to handle clients’ read/write requests. User data is stored as objects (it seems not the same with frontend object storage RADOSGW) in a backend object store.
Backend Object Store: Filestore vs Bluestore #
Initially Ceph utilized Filestore, but now it has been replaced by more efficient object store Bluestore.
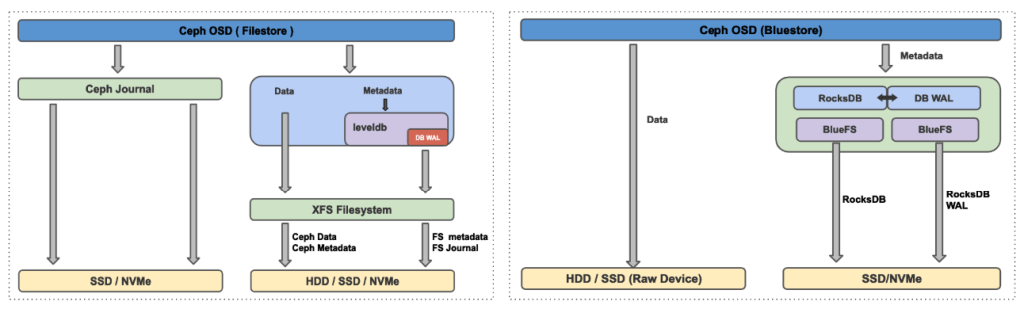
In filestore, objects are written to a file system (xfs, ext4, btrfs). Unlike the filestore, Bluestore stores objects directly on the block devices without any file system interface, and manages metadata with RocksDB. Direct access to block devices reduces software overheads coming from Linux kernel file system software stack, hence increases performance. Detailed benchmark results can be seen in [here].
BlueStore (/src/os/bluestore) 4 #
In order to step up on top of the current implementation, I further investigate bluestore. The term BlueStore means Block + NewStore.
- Objects can be called as a set of byte stream data plus metadata. Instead of storing the infromation through a file system, BlueStore stores data directly to the raw block devices, and metadata to RocksDB key/value store and BlueFS.
- BlueFS implements a minimal file system to allow RocksDB to store files on it, and it shares raw device with BlueStore 5.
Ceph Monitors (MONs) (/src/mon) #
ceph-mon is the cluster monitor daemon, forming a Paxos part-time parliament cluster.
It maintains maps of the cluster state, including the monitor map, manager map, the OSD map, and the CRUSH map 6.
Summary #
- Ceph is a framework for distributed storage cluster. It consists of the frontend client framework, including several RADOS-based file access interfaces, the backend storage framework, including daemons (OSDs, MONs, managers) and backend object stores.
- Frontend client framework is based on RADOS (Reliable Autonomic Distributed Object Store). Clients can directly access to Ceph storage clusters with librados, but also can use RADOSGW (object storage), RBD (block storage), and CephFS (file storage).
- Backend server framework consists of several daemons that manage nodes, and backend object store to store users’ actual data.
In the next posts, I would like to explore more details of each parts.