Analyzing Gdev
Table of Contents
Gdev #
Gdev is an open-source CUDA software, containing device drivers, CUDA runtimes, CUDA/PTX compilers, and so on.
You can download it from [here].
Detail implementations are described in the other paper that the author wrote, Implementing Open-Source CUDA Runtime. (link)
Internal Implementation #
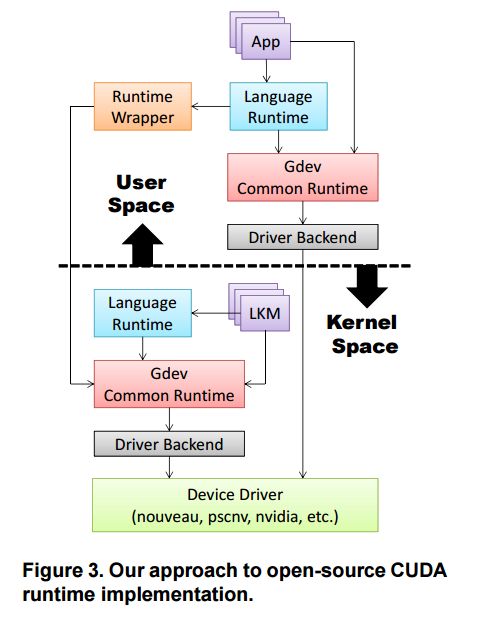
- Implementation of Gdev
Gdev uses the existing open-source NVIDIA device driver, Nouveau. It also supports NVIDIA proprietary drivers and pscnv as well, pscnv is not maintained and NVIDIA driver is not an open-source. Gdev mainly works well with Nouveau.
It supports user-space runtime, so it can perform a GPGPU application with only Nouveau device driver. However, it requires root permission to be executed, I uses additional device driver called gdev. To use it, compile Gdev with the following commands.
$ cmake -H. -Brelease -Ddriver=nouveau -Duser=OFF -Druntime=ON
$ make -C release -j 8
$ sudo make -C release install
Different from the instruction in the author’s Github, I set user parameter OFF to make driver backend reside in kernel space, so running CUDA application do not require root permission.
Code Review #
Gdev follows GPU’s resource management model, which is illustrated in [here]. So it allocates memory regions in MMIO, writes commands into that MMIO region, and so on. This section will analyze function calls from a basic example CUDA application.
The sample application calls CUDA device API functions as follows.
cuInit()
cuDeviceGet()
cuCtxCreate()
cuModuleLoad()
cuModuleGetFunction()
cuFuncSetBlockShape()
cuMemAlloc(a[])
cuMemAlloc(b[])
cuMemAlloc(c[])
cuMemcpyHtoD(a[])
cuMemcpyHtoD(b[])
cuParamSeti() ...
cuParamSetSize()
cuLaunchGrid()
cuCtxSynchronize()
cuMemcpyDtoH(c[])
cuMemFree(a[])
cuMemFree(b[])
cuMemFree(c[])
cuModuleUnload()
cuCtxDestroy()
0. Additional Functions in Nouveau #
All gdev functions call functions additionally implemented in Nouveau (/linux/drivers/gpu/drm/nouveau/gdev_interface.c). This file does not exist by default and Linux kernel should be patched by a patcher that the author provided.
int gdev_drv_vspace_alloc(struct drm_device *drm, uint64_t size, struct gdev_drv_vspace *drv_vspace) {
u32 arg0 = 0xbeef0201;
u32 arg1 = 0xbeef0202;
printk("%s: creating a new vspace. size: 0x%lx\n",
__func__, size);
nouveau_channel_new(nvdrm, &nvdrm->client, NVDRM_DEVICE, NVDRM_CHAN + 2, arg0, arg1, &chan);
...
}
int gdev_drv_chan_alloc(struct drm_device *drm, struct gdev_drv_vspace *drv_vspace, struct gdev_drv_chan *drv_chan) {
// It initializes FIFO push buffer(`drv_chan->pb_xx`) and FIFO indirect buffer(`drv_chan->ib_xx`).
pb_order = 16; // it's hardcoded.
pb_bo = chan->push.buffer;
pb_base = chan->push.vma.offset;
...
pb_size = (1 << pb_order);
...
printk("%s: allocating a channel. "
"push buffer addr: 0x%lx, size: 0x%lx. "
"indirect buffer addr: 0x%lx\n",
__func__, pb_base, pb_size, ib_base);
// FIFO init: it has already been done in gdev_vas_new().
}
int gdev_drv_bo_alloc(struct drm_device *drm, uint64_t size, uint32_t drv_flags, struct gdev_drv_vspace *drv_vspace, struct gdev_drv_bo *drv_bo) {
printk("%s: allocating a new buffer object. size: 0x%lx\n",
__func__, size);
nouveau_bo_new(drm, size, 0, flags, 0, 0, NULL, &bo);
if (drv_flags & GDEV_DRV_BO_MAPPABLE) nouveau_bo_map(bo);
// allocate virtual address space, if requested.
if (drv_flags & GDEV_DRV_BO_VSPACE){
vma = kzalloc(sizeof(*vma), GFP_KERNEL);
nouveau_bo_vma_add(bo, client->vm, vma);
drv_bo->addr = vma->offset;
}
// address, size, and map.
drv_bo->map = bo->kmap.virtual;
drv_bo->size = bo->bo.mem.size;
driv_bo->priv = bo;
}
1. cuCtxCreate() #
Defined in /gdev/cuda/driver/context.c.
CUresult cuCtxCreate_v2(CUcontext *pctx, unsigned int flags, CUdevice dev) {
handle = gopen(minor);
// set to the current context.
cuCtxPushCurrent(ctx);
// get the CUDA-specific device information.
gquery(handle, GDEV_QUERY_CHIPSET, &cuda_info->chipset);
cuDeviceGetAttribute(&mp_count, CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUND, dev);
return CUDA_SUCCESS;
}
As cuCtxPushCurrent() and gquery() does not use any Nouveau driver function, they will be passed.
1-1. gopen() #
When cuCtxCreate() is called, the selected gdev device is opened. The function for this purpose is gopen(). It is implemented in /gdev/common/gdev_api.c and will be copied into /gdev/release/mod/gdev/gdev_api.c after performing cmake.
It opens the device as well as allocates some memory regions for this context.
struct gdev_handle *gopen (int minor) {
// open the specified device.
printk("%s: opening minor device number %d\n", __func__, minor);
struct gdev_device* gdev = gdev_dev_open(minor);
// create a new virtual address space (VAS) object.
printk("%s: creating a new virtual address space object. size: 0x%lx\n",
__func__, GDEV_VAS_SIZE);
gdev_vas_t* vas = gdev_vas_new(gdev, GDEV_VAS_SIZE, h);
// create a new GPU context object.
printk("%s: creating a new GPU context.\n", __func__);
gdev_ctx_t* ctx = gdev_ctx_new(gdev, vas);
// allocate static bounce bound buffer objects.
printk("%s: allocating static bounce bound buffer. size: 0x%lx\n",
__func__, GDEV_CHUNK_DEFAULT_SIZE);
gdev_mem_t* dma_mem = __malloc_dma(vas, GDEV_GDEV_CHUNK_DEFAULT_SIZE, h->pipeline_count);
GDEV_PRINT("Opened gdev%d\n", minor);
}
Note that gdev_drv_chan_alloc() says FIFO buffers are initiated by gopen(), not by itself. To check this, I also added a printk call in nouveau_fifo_channel_create_() function in linux/drivers/gpu/drm/nouveau/core/engine/fifo/base.c.
Result #
gopen: opening minor device 0
gopen: creating a new virtual address space object. size: 0x10000000000
gdev_drv_vspace_alloc: creating a new vspace. size: 0x10000000000
nouveau_fifo_channel_create_: channel addr: 0xe8002000, len: 0x1000.
gopen: creating a new GPU context. [1]
gdev_drv_chan_alloc: allocating a channel. push buffer addr: 0x103f5000, size: 0x10000. indirect buffer addr: 0x10405000
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x10000
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x8
gopen: allocating static bounce bound buffer. size: 0x40000 [2]
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x40000 (memory allocated at host for DMA)
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x40000 (memory allocated at host for DMA)
[gdev] Opened gdev0
Note that FIFO buffer is created by gopen().
[1] gdev_ctx_new() #
gdev_ctx_new() is defined in /gdev/common/gdev_nvidia.c, and calls gdev_raw_ctx_new() defined in /gdev/mod/gdev/gdev_drv_nvidia.c, which allocates three buffers: command FIFO, fence buffer, and notify buffer.
Actually, it creates one more buffer (desc buffer), however, it is allocated for Kepler GPU architecture, which will not be used by me.
struct gdev_ctx *gdev_raw_ctx_new(struct gdev_device *gdev, struct gdev_vas *vas) {
struct gdev_ctx* ctx = kzalloc(sizeof(*ctx), GFP_KERNEL);
gdev_drv_chan_alloc(drm, &vspace, &chan);
...
// fence buffer.
flags = GDEV_DRV_BO_SYSRAM | GDEV_DRV_BO_VSPACE | GDEV_DRV_BO_MAPPABLE;
gdev_drv_bo_alloc(drm, GDEV_FENCE_BUF_SIZE, flags, &vspace, $fbo);
// notify buffer.
flags = GDEV_DRV_BO_VRAM | GDEV_DRV_BO_VSPACE;
gdev_drv_bo_alloc(drm, 8 /* 64 bits */, flags, &vspace, &nbo);
// compute desc buffer.
flags = GDEV_DRV_BO_SYSRAM | GDEV_DRV_BO_VSPACE | GDEV_DRV_BO_MAPPABLE;
gdev_drv_bo_alloc(drm, sizeof(struct gdev_nve4_compute_desc), flags, &vpsace, &dbo);
...
// allocating PGRAPH context for M2MF
gdev_drv_subch_alloc(drm, ctx->pctx, 0xbeef323f, m2mf_class, &m2mf);
return ctx;
}
After adding printk()s in gdev_raw_ctx_new(), the result is as follows.
gdev_drv_chan_alloc: allocating a channel. push buffer addr: 0x103f5000, size: 0x10000. indirect buffer addr: 0x10405000
gdev_raw_ctx_new: fence buffer allocation with size: 0x10000
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x10000
gdev_raw_ctx_new: notify buffer allocation with size: 0x8
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x8
...
[2] __malloc_dma() #
The result says that __malloc_dma() allocates two buffer objects and memory regions each size of which is 0x40000.
Here is a detailed implementation of __malloc_dma(). It is located in /gdev/common/gdev_api.c.
static gdev_mem_t** __malloc_dma(gdev_vas_t *vas, uint64_t size, int p_count) {
gdev_mem_t** dma_mem;
int i;
for (i=0; i<p_count; i++) dma_mem[i] = gdev_mem_alloc(vas, size, GDEV_MEM_DMA);
...
}
gdev_mem_alloc() calls gdev_raw_mem_alloc(), which calls gdev_drv_bo_alloc(). After printing p_count, I found that p_count is 2. Hence two memory and buffer objects are allocated.
2. cuModuleLoad() #
Defined in /gdev/cuda/driver/module.c.
CUresult cuModuleLoad(CUmodule *module, const char *fname) {
...
// load the cubin image from the given object file.
gdev_cuda_load_cubin_file(mod, fname);
// construct the kernels based on the cubin data.
gdev_cuda_construct_kernels(mod, &ctx->cuda_info);
// allocate (local) static data memory.
printf("%s: allocating local static data memory. size: 0x%lx\n",
__func__, mod->sdata_size);
gmalloc(handle, mod->sdata_size);
// allocate the static data information for each kernel.
gdev_cuda_locate_sdata(mod);
// allocate code and constant memory.
printf("%s: allocating code and constant memory size. size: 0x%lx\n",
__func__, mode->code_size);
gmalloc(handle, mod->code_size);
// locate the code information for each kernel.
gdev_cuda_locate_code(mod);
// transfer the code and constant memory onto the device.
bnf_buf = malloc(mod->cuda_size);
gdev_cuda_memcpy_code(mod, bnc_buf);
gmemcpy_to_device(handle, mod->code_addr, bnc_buf, mod->code_size);
...
}
Note that this is a runtime library, not a part of gdev device driver, so printf() should be used instead of using printk(). Hence results are divided into userspace part, and kernel dmesg part. Note that I also added more printk() function calls in gdev_raw_mem_alloc_dma() and gdev_raw_mem_alloc(), which are implemented in /gdev/common/gdev_nvidia_mem.c. These functions are called by gmalloc(), as follows.
uint64_t gmalloc(struct gdev_handle *h, uint64_t size) {
...
printk("%s: allocating device memory by calling gdev_mem_alloc. size: 0x%lx\n",
__func__, size);
mem = gdev_mem_alloc(vas, size, GDEV_MEM_DEVICE);
...
}
struct gdev_mem *gdev_mem_alloc(struct gdev_vas *vas, uint64_t size, int type) {
switch (type) {
case GDEV_MEM_DEVICE:
mem = gdev_raw_mem_alloc(vas, size);
break;
case GDEV_MEM_DMA:
mem = gdev_raw_mem_alloc_dma(vas, size);
break;
default:
goto fail;
}
}
Result #
stdout
cuModuleLoad: allocating local static data memory. size: 0xc00000
cuModuleLoad: code and constant memory size: 0x20300
dmesg
__malloc_dma: allocating 2 memory regions with size 0x40000
gdev_raw_mem_alloc_dma: allocating memory at host for DMA. size: 0x40000
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x40000
gdev_raw_mem_alloc_dma: allocating memory at host for DMA. size: 0x40000
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x40000
gmalloc: allocating device memory by calling gdev_mem_alloc. size: 0xc00000
gdev_raw_mem_alloc: allocing memory at device. size: 0xc00000
gdev_drv_bo_alloc: allocating a new buffer object. size: 0xc00000
gmalloc: allocating device memory by calling gdev_mem_alloc. size: 0x20300
gdev_raw_mem_alloc: allocating memory at device. size: 0x20300
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x20300
I understand two gmalloc()s are called for static data and code/constant memory, but where does two buffer object allocation come from?
This __malloc_dma() call comes from gtune(), defined in /gdev/common/gdev_api.c, which is called by gopen() in CUDA runtime library (defined in /gdev/lib/kernel/gdev_lib.c).
struct gdev_handle *gopen(int minor) {
...
sprintf(devname, "/dev/gdev%d", minor);
fd = open(devname, O_RDWR);
...
// chunk size of 0x40000 seems best when using OS runtime.
gtune(h, GDEV_TUNE_MEMCPY_CHUNK_SIZE, 0x40000);
}
/gdev/common/gdev_api.c
int gtune (struct gdev_handle *h, uint32_t type, uint32_t value) {
switch(type){
case GDEV_TUNE_MEMCPY_PIPELINE_COUNT:
...
case GDEV_TUNE_MEMCPY_CHUNK_SIZE:
h->dma_mem = __malloc_dma(h->vas, h->chunk_size, h->pipeline_count);
}
}
When fd = open(devname, O_RDWR) is called, the control is transferred to gdev device driver, and calls gdev_open(), defined in /gdev/mod/gdev/gdev_fops.c, which calls gopen() function, defined in the gdev device driver, not runtime library.
Hence, actually, this allocations are parts of cuCtxCreate().
The call flow is as follows. cuCtxCreate() -> gopen() (in CUDA runtime) -> gdev_open() (in gdev device driver) -> gopen() (in gdev device drvier).
3. cuMemAlloc() #
// a[]
gmalloc: allocating device memory by calling gdev_mem_alloc. size: 0x24
gdev_raw_mem_alloc: allocating memory at device. size: 0x24
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x24
// b[]
gmalloc: allocating device memory by calling gdev_mem_alloc. size: 0x24
gdev_raw_mem_alloc: allocating memory at device. size: 0x24
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x24
// c[]
gmalloc: allocating device memory by calling gdev_mem_alloc. size: 0x24
gdev_raw_mem_alloc: allocating memory at device. size: 0x24
gdev_drv_bo_alloc: allocating a new buffer object. size: 0x24
4. cuMemcpyHtoD() #
4-1. How gdev transfer the data into device? #
Defined in /gdev/cuda/driver/memory.c.
CUresult cuMemcpyHtoD_v2 (CUdeviceptr dstDevice, const void *srcHost, unsigned int ByteCount) {
...
gmemcpy_to_device(handle, dst_addr, src_buf, size);
return CUDA_SUCCESS;
}
/gdev/common/gdev_api.c
int gmemcpy_to_device(struct gdev_handle *h, uint64_t dst_addr, const void *src_buf, uint64_t size) {
return __gmemcpy_to_device(h, dst_addr, src_buf, size, NULL, __ f_memcpy);
}
// a wrapper function of gmemcpy_to_device().
static int __gmemcpy_to_device (struct gdev_handle *h, uint64_t dst_addr, const void *src_buf, uint64_t size, uint32_t *id, int (*host_copy)(void*, const void*, uint32_t)) {
mem = gdev_mem_lookup_by_addr(vas, dst_addr, GDEV_MEM_DEVICE);
gdev_mem_lock(mem);
__gmemcpy_to_device_locked(ctx, dst_addr, src_buf, size, id, ch_size, p_count, vas, mem, dma_mem, host_copy);
gdev_mem_unlock(mem);
...
}
static int __gmemcpy_to_device_locked(gdev_ctx *ctx, uint64_t dst_addr, const void *src_buf, uint64_t size, uint32_t *id, uint32_t ch_size, int p_count, gdev_vas_t *vas, gdev_mem_t *mem, gdev_mem_t **dma_mem, int (*host_copy)(void*, const void*, uint32_t)) {
if (size <= 4 && mem->map)
gdev_write32(mem, dst_addr, ((uint32_t*)src_buf)[0]);
// GDEV_MEMCPY_IOWRITE_LIMIT = 0x400000 (4MB) defined in mod/gdev/gdev_conf.h
else if (size <= GDEV_MEMCPY_IOWRITE_LIMIT && mem->map)
gdev_write(mem, dst_addr, src_buf, size);
else if ((hmem = gdev_mem_lookup_by_buf(vas, src_buf, GDEV_MEM_DMA))) {
__gmemcpy_dma_to_device(ctx, dst_addr, hmem->addr, size, id);
}
else {
// prepare bounce buffer memory.
// In a test configuration, it is not called.
if(!dma_mem) bmem = __malloc_dma(vas, __min(size, ch_size), p_count);
if (p_count > 1 && size > ch_size) __gmemcpy_to_device_p(ctx, dst_addr, src_buf, size, ch_size, p_count, bmem, host_copy);
else __gmemcpy_to_device_np(dst_addr, src_buf, size, ch_size, bmem, host_copy);
if(!dma_mem) __free_dma(bmem, p_count);
}
}
The last function calls gdev_write32() or gdev_write(), both are defined in /mod/gdev/gdev_nvidia_compute.c. Also you can see that gdev transfers data in different ways in terms of its size.
- If size is less than 4 bytes, it just write 4 bytes (32 bits) via MMIO.
- If size is less than 4MB, it uses MMIO (maybe).
- Else, it transfers via DMA.
This strategy is well explained in the paper Data Transfer Matters for GPU Computing [[link](http://www.ertl.jp/~shinpei/papers/icpads13.pdf)]. The author of Gdev is a coworker of this paper.
gdev_write32() and gdev_write() call gdev_raw_write32() and gdev_raw_write() respectively, defined in /mod/gdev/gdev_drv_nvidia.c.
void gdev_raw_write32 (struct gdev_mem *mem, uint64_t addr, uint32_t val) {
bo.addr = mem->addr;
bo.size = mem->size;
bo.map = mem->map;
gdev_drv_write32(drm, &vspace, &bo, offset, val);
}
void gdev_raw_write (struct gdev_mem *mem, uint64_t addr, const void *buf, uint32_t size) {
bo.addr = mem->addr;
bo.size = mem->size;
bo.map = mem->map;
gdev_drv_write(drm, &vspace, &bo, offset, size, buf);
}
/linux/drivers/gpu/drm/nouveau/gdev_interface.c
int gdev_drv_write32 (struct drm_device *drm, struct gdev_drv_vspace *drv_vspace, struct gdev_drv_bo *drv_bo, uint64_t offset, uint32_t val) {
if(drv_bo->map) iowrite32_native(val, drv_bo->map + offset);
return 0;
}
int gdev_drv_write (struct drm_device *drm, struct gdev_drv_vspace *drv_vspace, struct gdev_drv_bo *drv_bo, uint64_t offset, uint64_t size, const void *buf) {
if(drv_bo->map) memcpy_toio(drv_bo->map + offset, buf, size);
}
/linux/include/asm-generic/io.h
static inline void memcpy_toio(volatile void __ iomem *addr, const void*buffer, size_t size) {
memcpy(__ io_virt(addr), buffer, size);
}
static inline void iowrite32 (u32 value, volatile void __ iomem *addr) {
writel(value, addr);
}
These functions are for MMIO defined in Linux kernel. For more information, visit [[here](http://www.makelinux.net/ldd3/chp-9-sect-4)].
4-2. How gdev get the MMIO address for the variable? #
Now, we understand that the target address is drv_bo->map + offset (gdev_drv_write()), the first one of which comes from mem->map(gdev_raw_write()), which returns from gdev_mem_lookup_by_addr() in __gmemcpy_to_device().
Seeing __gmemcpy_to_device() again, the function works as follows.
static int __gmemcpy_to_device (struct gdev_handle *h, uint64_t dst_addr, const void *src_buf, uint64_t size, uint32_t *id, int (*host_copy)(void*, const void*, uint32_t)) {
mem = gdev_mem_lookup_by_addr(vas, dst_addr, GDEV_MEM_DEVICE);
__gmemcpy_to_device_locked(ctx, dst_addr, src_buf, size, id, ch_size, p_count, vas, mem, dma_mem, host_copy);
...
}
Keep in mind that, all software must access to memory including MMIO via virtual address, not physical address. hence, what gdev_mem_lookup_by_addr returns is a virtual address mapped to dst_addr. For a[], printing the information is as follows.
gdev_mem *mem = gdev_mem_lookup_by_addr(vas, dst_addr, GDEV_MEM_DEVICE);
printk("%s: gdev_mem_lookup_by_addr returns mem->map: 0x%lx, dst_addr: 0x%lx\n",
__func__, mem->map, dst_addr);
dmesg
// cuMemAlloc for a[]
gmalloc: calling gdev_mem_alloc, size: 0x24.
gdev_raw_mem_alloc: allocating memory at device. size: 0x24
__gdev_raw_mem_alloc: allocating memory of 0x24 bytes at addr 0x10554000
...
// cuMemcpyHtoD for a[]
__gmemcpy_to_device: gdev_mem_lookup_by_addr returns mem->map: 0xffffc90010e9c000, dst_addr: 0x10554000
As the name of the function is lookup_by_addr, and dst_addr is given as a parameter, gdev_mem structure would store both physical address and virtual address mapped to it.
For more detail, let’s see implementation of the function to see how it get objects with dst_addr. It is implemented in /gdev/common/gdev_nvidia_mem.c.
struct gdev_mem *gdev_mem_lookup_by_addr(struct gdev_vas *vas, uint64_t addr, int type) {
switch (type){
case GDEV_MEM_DEVICE:
gdev_list_for_each (mem, &vas->mem_list, list_entry_heap) {
if (addr >= mem->addr) && (addr < mem->addr + mem->size)) break;
}
...
}
return mem;
}
It compares dst_addr with mem->addr for all gdev_mem objects.
Then let’s figure out when gdev_mem object is created for each data. One good starting point would be __gdev_raw_mem_alloc(), defined in /gdev/mod/gdev/gdev_drv_nvidia.c.
static intline struct gdev_mem *__gdev_raw_mem_alloc(struct gdev_vas *vas, uint64_t size, uint32_t flags) {
struct gdev_mem* mem;
mem = kzalloc(sizeof(*mem), GFP_KERNEL);
gdev_drv_bo_alloc(drm, size, flags, &vpsace, &bo);
printk("%s: allocating memory of 0x%lx bytes at addr 0x%lx\n",
__func__, size, bo.addr);
mem->addr = bo.addr;
mem->size = bo.size;
mem->map = bo.map;
mem->bo = bo.priv;
mem->padata = (void*)drm;
return mem;
}
__gdev_raw_mem_alloc: allocating memory of 0x24 bytes at addr 0x10554000
Hence mem->addr = bo.addr. Then how bo.addr is set? It is set in gdev_drv_bo_alloc() defined in /linux/drivers/gpu/drm/nouveau/gdev_interface.c.
int gdev_drv_bo_alloc (struct drm_device *drm, uint64_t size, uint32_t drv_flags, struct gdev_drv_vspace *drv_vspace, struct gdev_drv_bo *drv_bo) {
struct nouveau_bo* bo;
nouveau_bo_new(drm, size, 0, flags, 0, 0, NULL, &bo);
...
nouveau_vma* vma - kzalloc(sizeof(*vma), GFP_KERNEL);
nouveau_bo_vma_add(bo, client->vm, vma);
drv_bo->addr = vma->offset;
// otherwise drv_bo->addr will be 0.
drv_bo->map = bo->kmap.virtual;
drv_bo->size = bo->bo.mem.size;
drv_bo->priv = bo;
return 0;
}
Returned bo by nouveau_bo_new() seems to set the target phyiscal address.