LLM Inference: Continuous Batching and PagedAttention
Table of Contents
Recent days, many papers have been published to optimize LLM inference. This post introduces two of them, which focus on improving throughput by exploiting characteristics of batched LLM serving and characteristics of attention.
Orca #
Orca, published in OSDI'22, proposes two novel techniques: 1. continuous batcing (or iteration-level scheduling) 1, and 2. selective batching.
Continuous Batching #
Before the introduction of continuous batching, static batching starts batch at once and wait all batch to complete their computation. But because we have no idea how many tokens will be generated per request, this leaves so much time slots of GPU idle and underutilized.
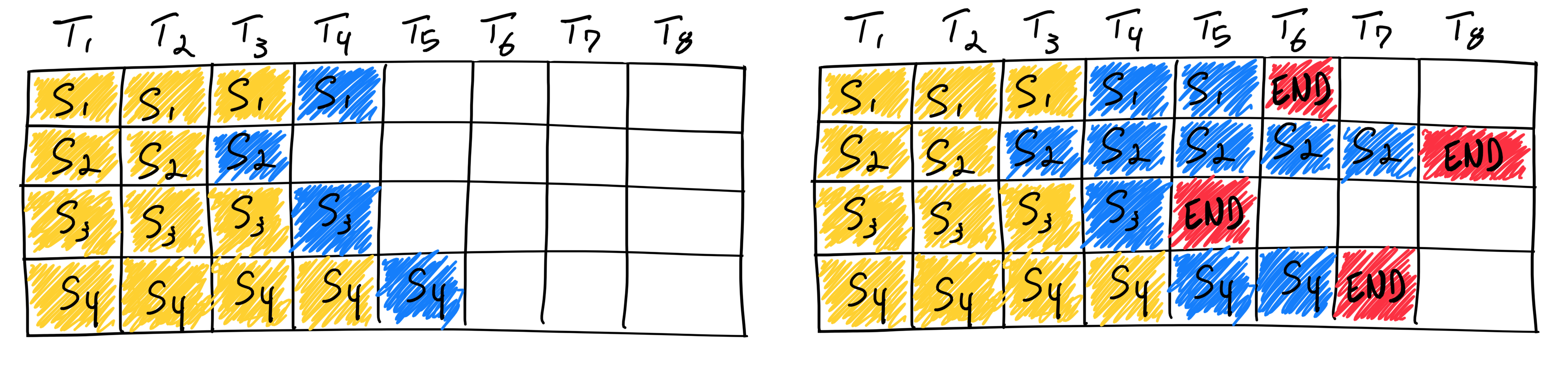
Orca, instead, introduces continuous batching; instead of waiting for all batches to complete before starting a new batch, it continuously schedules a new request when a request in the processing batch completes and slots are available.
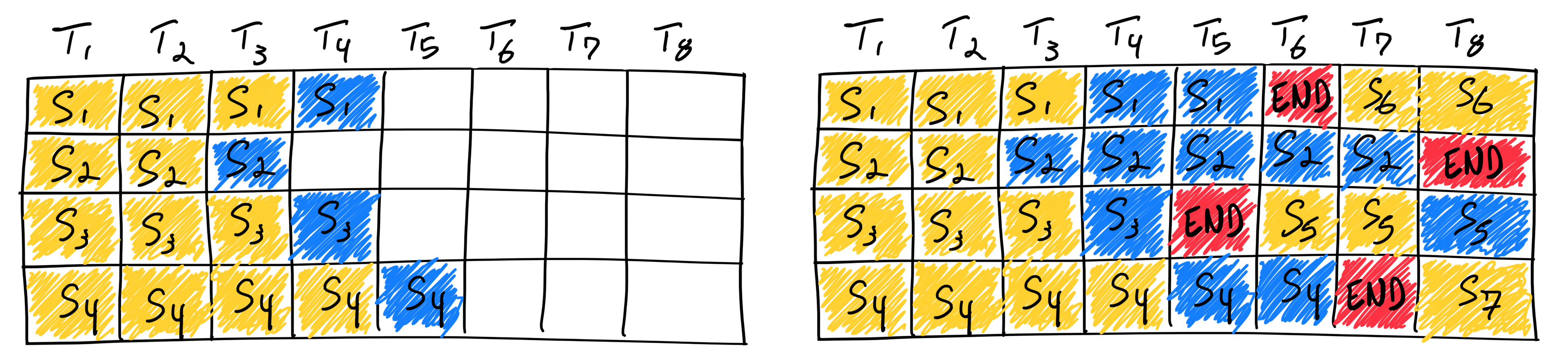
Selective Batching #
Precisely, the illustration of continuous batching above is not correct; Orca does not split prefill stages into multiple iterations, and they do not even batch attentions at all.
This is because, for batch process, torch.bmm is typically used, however, two input tensors must have a strict shape: [b, n, m] and [b, m, p] so that output can be a [b, n, p] shaped tensor.
If we batch requests with different number of tokens as an example:
- for request 1, K and V cache shape is
[D, 4, D/H](4 tokens), - for request 2, K and V cache shape is
[D, 7, D/H](7 tokens),
which cannot be coalesced into a sigle tensor of shape [2, D, ?, D/H] for batched matmul.
However, they observe that all non-Attention operations (Linear, GeLU, etc) are number of token-independent operations; thus they selectively batch those operations, while sequencially execute attentions after splitting the input:
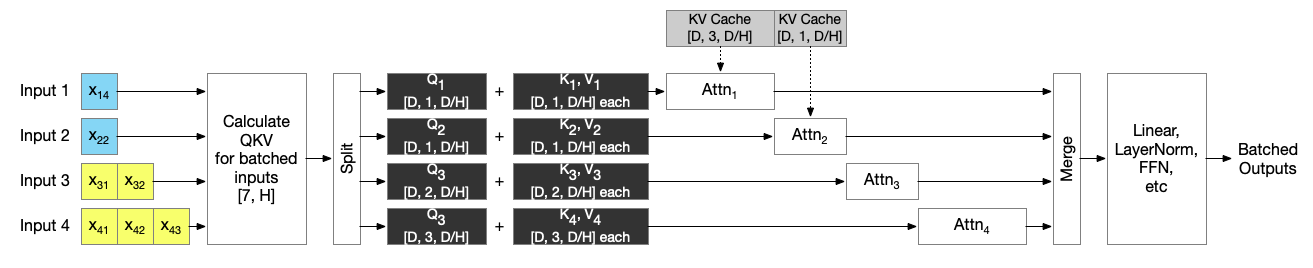
This can easily be optimized with kernel fusion. PagedAttention, which I will introduce below, fuses all attentions for a given batch and execute in a single global CUDA kernel named paged_attention_kernel (Orca is not open sourced). As long as matrix multiplications are done within a single CUDA kernel, they are fused and performance are improved.
In the opposite, HuggingFace transformer’s naive implementation uses torch API and calls torch.bmm, torch.nn.functional.softmax, torch.nn.functional.dropout; this is much slow due to overheads between CUDA calls.
Use FlashAteention with HuggingFace transformers to boost performance. A fused flash attention is called. For more information, visit flash attention repository and read this paper.
PagedAttention 2 #
After the introduction of continous batching, PagedAttention is introduced to solve inefficiency of memory consumption due to KV caching.
One drawback of Orca is that they reserve memory for KV cache with the maximum number of tokens:
When the scheduler considers a request in the initiation phase, meaning that the request has never been scheduled yet, the scheduler uses the request’s
max_tokensattribute to reservemax_tokensslots of GPU memory for storing the keys and values in advance.
Meaning, most of the reserved memory will not be used unless a request generates a lot of tokens.
PagedAttention, instead, allocates GPU memory slots on demand to reduce such internal fragmentation. It partitions the KV cache of each sequence into KV blocks, where each block contains the key and value vectors for a fixed number of tokens.
When it starts forward pass, a new KV block is allocated to a request, and fill KV cache slots in it. When the block is filled, a new block can be allocated.
Preemption with Page Miss #
As the entire cache size is fixed, it can run out of available blocks to store the newly genereated KV cache. In deciding which blocks should be evicted, PagedAttention interestingly implements all-of-nothing eviction policy, evicting all caches to either CPU (swapping) or discarding them (and later recompute it). The decision was because that all blocks of a sequence are accessed together, so it was not reasonable to remain some cache blocks for a sequence. A set of sequences (the latest requests will be preempted first) is selected and their blocks are evicted; while the eviction is in progress, they stop processing the sequences, if the sequence was in progress. After that, if the sequence was in progress, evicted blocks will be brought back to the GPU memory and finish execution.
This preemption is done when sheduling requests, not during runtime. Before scheduling requests, it first assigns a page slot to all running requests; if it is not available, do preemption and then run requests. Because PagedAttention implementes Orca’s iteration-level scheduling, it schedules requets (called SequenceGroup in implementation) every iteration by calling vllm.core.Scheduler._schedule():
# vllm.core.Scheduler._schedule()
# https://github.com/vllm-project/vllm/blob/v0.2.7/vllm/core/scheduler.py#L217-L237
def _schedule(self) -> SchedulerOutputs:
...
# Preserve new token slots for the running sequence groups.
running: List[SequenceGroup] = []
preempted: List[SequenceGroup] = []
while self.running: # type: List[SequenceGroup]
seg_group = self.runing.pop(0)
# try to append a new slot to the sequence group
while not self.block_manager.can_append_slot(seq_group):
# Entering here means we need to preempt some sequence groups to get slots.
# Until all running sequence group can get slots, iteration is executed.
if self.running:
# Preempt the lowest-priority sequence groups.
# Because this victim sequence group is no longer in self.running list,
# It cannot be re-added to running list, and will not be scheduled in this iteration.
victim_seq_group = self.running.pop(-1)
# Add victim_seq_group to either self.swapped or self.recomputed depending on preemption mode.
self._preempt(victim_seq_group, blocks_to_swap_out)
preempted.append(victim_seq_group)
else:
# No other sequence groups can be preempted.
# Preempt the current sequence group.
self._preempt(seq_group, blocks_to_swap_out)
preempted.append(seq_group)
break
else:
# Append new slots to the sequence group.
self._append_slot(seq_group, blocks_to_copy)
running.append(seq_group)
self.running = running
This _schedule() is called for every iteration (step):
# vllm.entrypoints.llm.LLM._run_engine()
# https://github.com/vllm-project/vllm/blob/main/vllm/entrypoints/llm.py#L184-L190
def _run_engine(self, usq_tqdm: bool) -> List[RequestOutput]:
...
while self.llm_engine.has_unfinished_requests():
step_outputs = self.llm_engine.step()
...
# vllm.engine.llm_engine.step()
def step(self) -> List[RequestOutput]:
seq_group_metadata_list, scheduler_outputs = self.scheduler.scheduler() # calls _schedule() inside
if not scheduler_outputs.is_empty():
# Execute the model.
all_outputs = self._run_workers(...)
output = all_outputs[0]
else:
output = []
return self._process_model_outputs(output, scheduler_outputs)
If swapping is completed, sequence groups can be re-scheduled. As they are moved from self.running to self.swapped after changinig its status to SequenceStatus.SWAPPED, they need to be re-moved to self.running:
# vllm.core.Scheduler._schedule()
# https://github.com/vllm-project/vllm/blob/v0.2.7/vllm/core/scheduler.py#L240-L262
if not preempted:
...
# Only add requests until the number of sequence group reaches to the maximum configured number.
num_curr_seqs = sum(seq_group.get_max_num_runing_seqs() for seq_group in self.running)
while self.swapped:
seq.group = self.swapped[0]
# If the sequence group cannot be swapped in, stop.
if not self.block_manager.can_swap_in(seq_group):
break
num_new_seqs = seq_group.get_max_num_running_seqs()
if num_curr_seqs + num_new_seqs > self.scheduler_config.max_num_seqs:
break
seq_group = self.swapped.pop(0)
self._swap_in(seq_group, blcoks_to_swap_in)
self._append_slot(seq_group, blocks_to_copy)
num_curr_seqs += num_new_seqs
self.running.append(seq_group)
Prompt Handling #
PagedAttention does not seem to coalesce prompt and decode requests in the same iteration, different from the illustration above.
In PagedAttention implementation, forward() checks whether the input is prompt:
if input_metadata.is_prompt:
# Prompt run.
else:
# Decoding run.
...
Because query, key, and value arguments include a batched input, all inputs should be either prompt or decode, and cannot be coalesced. This is also verified in Model Runner:
def prpare_input_tensors(...):
# NOTE: We assume that all sequences in the group are all prompts or
# all decodes.
is_prompt = seq_group_metadata_list[0].is_prompt
if is_prompt:
(input_tokens, input_positions, input_metadata, prompt_lens) = self._prepare_prompt(seq_group_metadata_list)
else:
(input_tokens, input_positions, input_metadata) = self._prepare_decode(seq_group_metadata_list)
prompt_lens = []
They might use several iterations, however, to finish all pending prompts before resuming decoding. Prompts can be grouped with padding or separated and executed in different iterations.