Kubernetes
Table of Contents
Kubernetes #
Kubernetes is is an container-based cluster orchestration tool, originally implemented by Google. It manages containerized workloads and services in clusters.
Kubernetes is really an orchestration tool?
Kubernetes does not call itself as an orchestration system, due to its different behaviors from the technical definition of “orchestration”.
Orchestration (from [Wikipedia])
Orchestration is the automated configuration, coordination, and management of computer systems and software.
Orchestration (from [bmc])
The goal of orchestration is to streamline and optimize frequent, repeatable processes to ensure accurate, speedier deployment of software. Anytime a process is repeatable and its tasks can be automated, orchestration can be used to optimize the process in order to eliminate redundancies.
Orchestration (from [Kubernetes])
In fact, Kubernetes eliminates the need for orchestration. The technical definition of orchestration is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes comprises a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C.
Well.. It depends on where to focus, but I rather think it is likely an orchestration tool.
Kubernetes manages a cluster, a set of machines (whether VMs or just physical machines). Each machine can be either:
- A master node: the cluster’s control plane. A cluster can contain multiple masters, which does not mean, however, they can serve multiple clusters, rather serves as backup nodes for the control plane for cluster’s high availability. It manages worker nodes.
- A (worker) node: hosts pods that are the components of applications. Actual user application workloads will be run in the worker nodes.
Master and Worker nodes are differnt from components from here, I think. The document says node components run on every node, which means including master nodes.
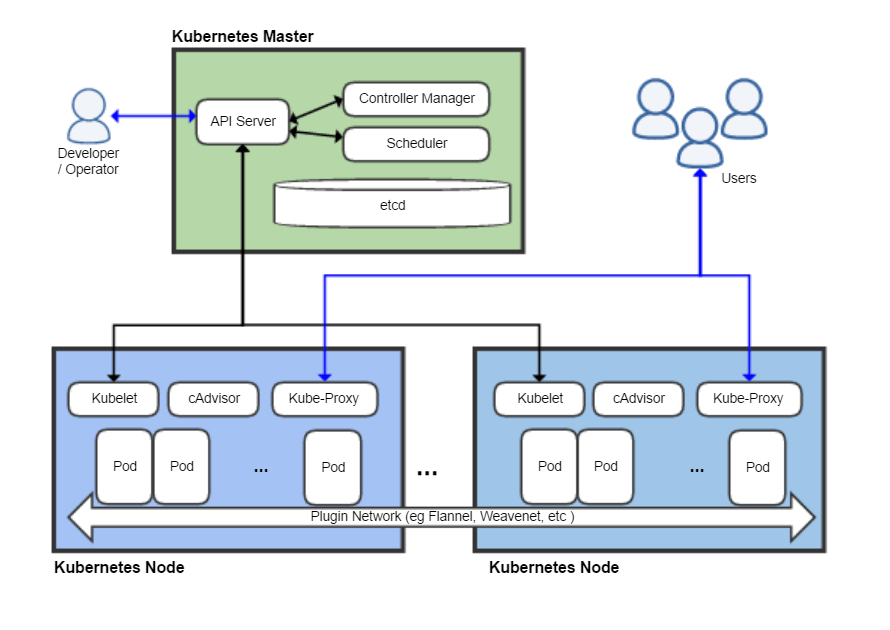
A master node contains the following Kubernetes components:
- A master node: kube-apiserver, etcd, kube-scheduler, kube-controller-manager, cloud-controller-manager, and all node components
- A worker node: all node components (kubelet, kube-proxy, and container runtime)
Details are well explained in [here].
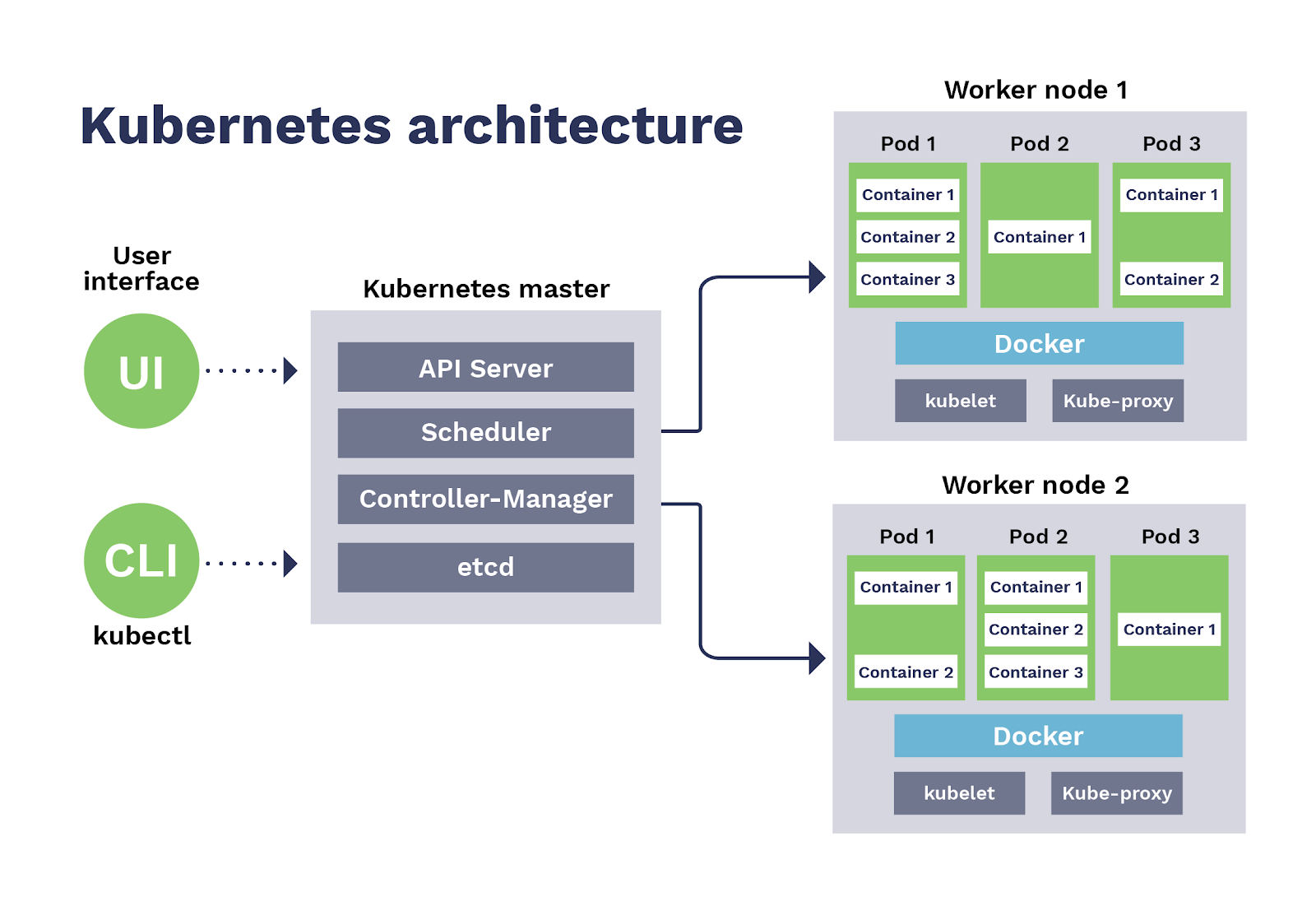
Pods #
A pod is a set of containers, the basic execution unit of a Kubernetes application, and the smallest unit in Kubernetes object model. This means the unit of deployment and migration is a pod, not a container. We should make a pod for our containerized application. It can contain only a single container, or multiple containers are allowed as well. If a pod contains multiple containers, they should be deployed together into the same worker node.
Why the Pod is introduced? In my thought it is mainly because communications between containers. Kubernetes runs with multiple nodes in the cluster and orchestrates applications, so applications do not know which node they will run on. Then how applications communicate each other without any knowledge (e.g. such as IP address) of nodes? The answer from Kubernetes is: use localhost.
Containers within a Pod share an IP address and port space, and can find each other via
localhost. They can also communicate with each other using standard inter-process communications like SystemV semaphores or POSIX shared memory.
Hence containerized applications in each pod are slightly different from traditional containers; those in the same pod share some namespaces: netns, ipcns, and optionally pidns.

Those shared Linux kernel resources are held by pause process in Infra container. The infra container is created algonside the corresponding pod, and whenever each container is created into the pod, its namespace and cgroup are shared to the container.