Open vSwitch in NVIDIA BlueField SmartNIC
Table of Contents
In embedded CPU (ECPF: Embedded CPU Physical Function) mode of NVIDIA BlueField DPU, Open vSwitch (OvS) is used for packet processing. Once BlueField Linux is installed, several frameworks are installed together as well, and OvS is one of them.
# in SmartNIC Linux
$ systemctl status openvswitch-switch
● openvswitch-switch.service - LSB: Open vSwitch switch
Loaded: loaded (/etc/init.d/openvswitch-switch; generated)
Active: active (running) since Sun 2022-01-16 18:17:46 UTC; 1 day 2h ago
Docs: man:systemd-sysv-generator(8)
Process: 227259 ExecStart=/etc/init.d/openvswitch-switch start (code=exited, status=0/SUCCESS)
Tasks: 13 (limit: 19074)
Memory: 111.5M
CGroup: /system.slice/openvswitch-switch.service
├─227323 ovsdb-server: monitoring pid 227324 (healthy)
├─227324 ovsdb-server /etc/openvswitch/conf.db -vconsole:emer -vsyslog:err -vfile:info ...
├─227341 ovs-vswitchd: monitoring pid 227342 (healthy)
└─227342 ovs-vswitchd unix:/var/run/openvswitch/db.sock -vconsole:emer -vsyslog:err ...
...
If SmartNIC is running in separated host mode, SmartNIC HW will automatically forward packets to the host and the SmartNIC, while in embedded mode, all packets first are handled by SmartNIC. Open vSwitch is running for this purpose: forwarding packets to the host.
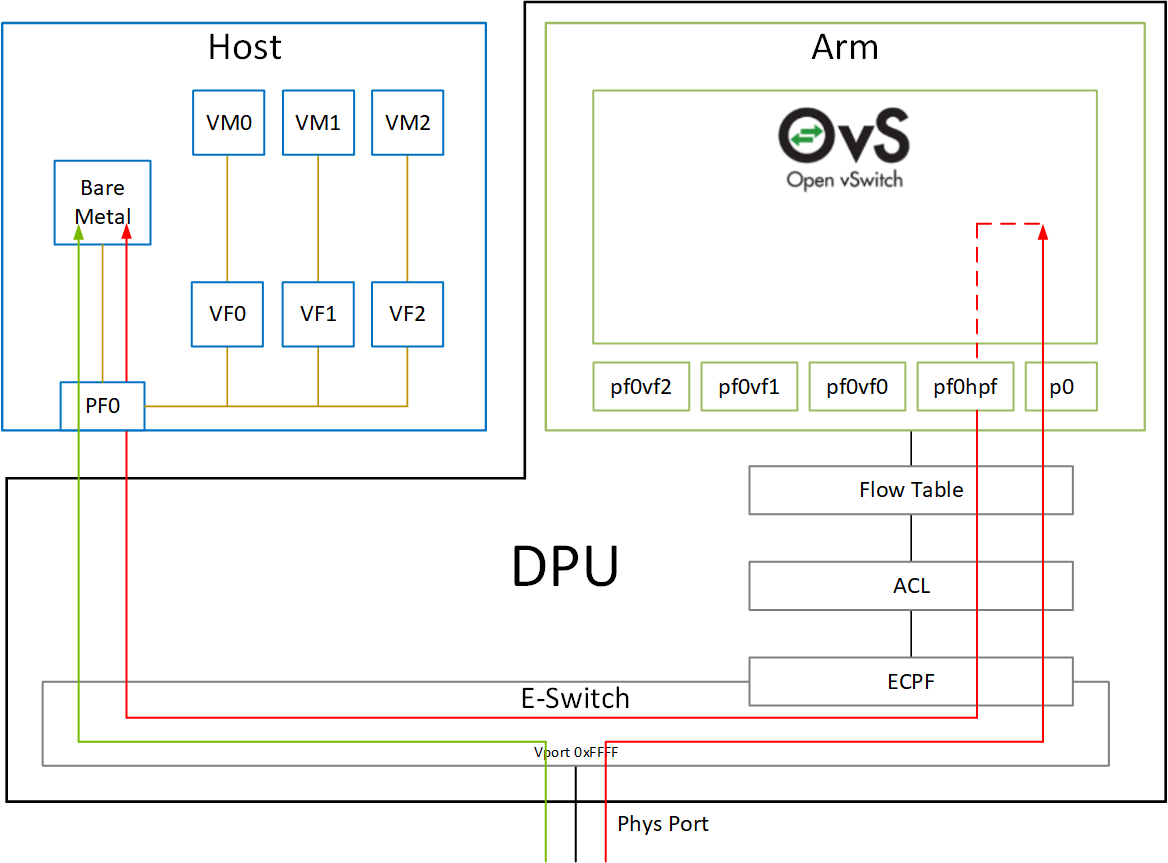
Is OvS Really Used in Host Packet Processing? #
Tutorial referenced: NVIDIA Mellanox Bluefield-2 SmartNIC Hands-On Tutorial Part VII/A: To Offload or Not To Offload? 1
To prove this, we could use OvS user-space tools. Here I setup two machines connected to each other via BlueField2 DPUs:
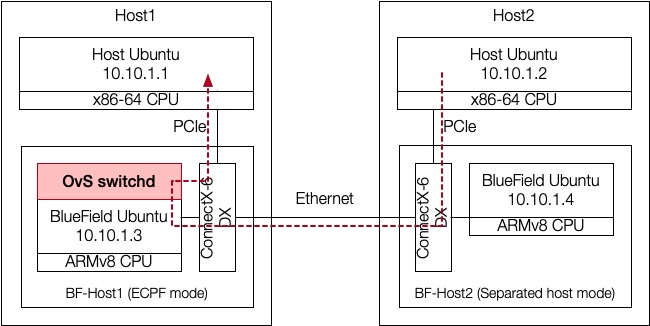
With default configuration, ping works:
# in BF-host1
bf-host1 $ ovs-vsctl show
Bridge ovsbr1
Port pf0hpf # connected to host ens5f0
Interface pf0hpf
Port en3f0pf0sf0 # this is for SmartNIC ubuntu network
Interface en3f0pf0sf0
Port ovsbr1 # Open vSwitch bridge
Interface ovsbr1
type: internal
Port p0 # physical port
Interface p0
ovs_version: "2.14.1"
bf-host1 $ ovs-ofctl dump-flows ovsbr1
cookie=0x0, duration=1.879s, table=0, n_packets=2, n_bytes=120, priority=0 actions=NORMAL
# in host2
host2 $ ping 10.10.1.1 -c 5
PING 10.10.1.1 (10.10.1.1) 56(84) bytes of data.
64 bytes from 10.10.1.1: icmp_seq=1 ttl=64 time=0.702 ms
64 bytes from 10.10.1.1: icmp_seq=2 ttl=64 time=0.343 ms
64 bytes from 10.10.1.1: icmp_seq=3 ttl=64 time=0.359 ms
64 bytes from 10.10.1.1: icmp_seq=4 ttl=64 time=0.408 ms
64 bytes from 10.10.1.1: icmp_seq=5 ttl=64 time=0.175 ms
But if we delete a default flow configuration, ping does not work:
# in BF-host1
bf-host1 $ over-ofctl del-flows ovsbr1
bf-host1 $ over-ofctl dump-flows ovsbr1
# nothing
# in host2
host2 $ ping 10.10.1.1 -c 5
PING 10.10.1.1 (10.10.1.1) 56(84) bytes of data.
--- 10.10.1.1 ping statistics ---
5 packets transmitted, 0 received, 100% packet loss, time 4076ms
After manually inserting OvS flow rules, it works again:
# in BF-host1
bf-host1 $ ovs-ofctl add-flow ovsbr1 ip,in_port=pf0hpf,actions=output:p0
bf-host1 $ ovs-ofctl add-flow ovsbr1 ip,in_port=p0,ip_dst=10.10.1.1,actions=output:pf0hpf
bf-host1 $ ovs-ofctl add-flow ovsbr1 arp,actions=FLOOD
# in host2
host2 $ ping 10.10.1.1 -c 5
PING 10.10.1.1 (10.10.1.1) 56(84) bytes of data.
64 bytes from 10.10.1.1: icmp_seq=1 ttl=64 time=0.522 ms
64 bytes from 10.10.1.1: icmp_seq=2 ttl=64 time=0.212 ms
64 bytes from 10.10.1.1: icmp_seq=3 ttl=64 time=0.166 ms
64 bytes from 10.10.1.1: icmp_seq=4 ttl=64 time=0.150 ms
64 bytes from 10.10.1.1: icmp_seq=5 ttl=64 time=0.142 ms
# in BF-host1
bf-host1 $ ovs-ofctl dump-flows ovsbr1
cookie=0x0, duration=67.595s, table=0, n_packets=5, n_bytes=490, ip,in_port=p0,nw_dst=10.10.1.1 actions=output:pf0hpf
cookie=0x0, duration=65.799s, table=0, n_packets=5, n_bytes=490, ip,in_port=pf0hpf actions=output:p0
cookie=0x0, duration=64.320s, table=0, n_packets=2, n_bytes=112, arp actions=FLOOD
Packets are captured by OvS (n_packets=5) in the flow dump result.
Explaining OvS Rules #
In setting OvS rules I used pf0hpf and p0 ports. NVIDIA DOCK SDK explains how these ports are connected to each other.
By default, Mellanox OFED installs the following ports:
bf-host1 $ ovs-vsctl show
Bridge ovsbr1
Port pf0hpf
Interface pf0hpf
Port en3f0pf0sf0
Interface en3f0pf0sf0
Port ovsbr1
Interface ovsbr1
type: internal
Port p0
Interface p0
ovs_version: "2.14.1"
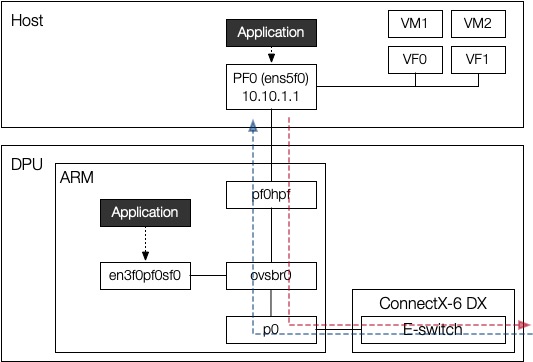
add-flow ovsbr1 ip,in_port=pf0hpf,actions=output:p0
This rule indicates the red line in the figure. When a packet comes from the port pf0hpf (hpf stands for host physical function), which is connected to the host interface (meaning outbound packet from the host), OvS should forward it to the physical port so that it can reach out to the destination (actions=output:p0). p0 is an actual physical port in DPU, connected to the network outside.
add-flow ovsbr1 ip,in_port=p0,ip_dst=10.10.1.1,actions=output:pf0hpf
This rule indicates the blue line in the figure, representing handling incoming packets. Note that an SF en3f0pf0sf0 can also have an IP and can be used by applications in ARM CPU, not all packets should be forward to the host. In this example, the host has 10.10.1.1 IP, so only packets with destination IP 10.10.1.1 (ip_dst=10.10.1.1) should be forwarded to pf0hpf port, which is connected to the host.
BlueField OvS Data Plane HW Offloading #
OvS datapath can be offloaded to the hardware for acceleration in NVIDIA BlueField2 DPU. It seems to have two hardware accelerators: tc-flower and ASAP2.
Kernel-OVS, OVS-TC, and tc-flower 2 #
Note that the reference is for Netronome Agilio SmartNICs, but I think it can also be applied to NVIDIA BlueField SmartNICs. Not sure it is a general feature for every SmartNICs.
Traffic Control (TC) flower is not a hardware, actually. It is a packet classifier in the Linux kernel, and part of the kernel traffic classification system. This TC datapath can be offloaded into SmartNIC, which provides a huge performance boost in virtual switch packet processing.
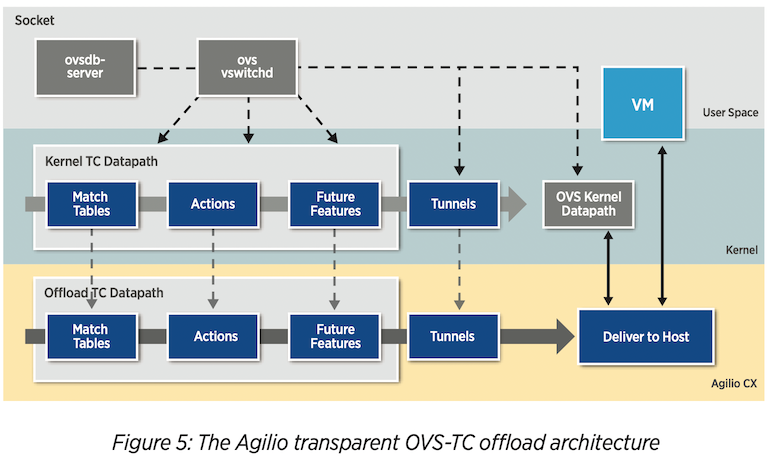
It seems NVIDIA BlueField2 also provides TC offload hardware acceleration. I followed the tutorial to test SmartNIC offloading.
To check whether HW offloading is enabled, use the following command in the BF2:
$ ovs-vsctl get Open_vSwitch . other_config:hw-offload
"true"
To change configuration, set value and restart OvS switch daemon:
$ ovs-vsctl set Open_vSwitch . other_config:hw-offload=true
$ systemctl restart openvswitch-switch
Note that when restart switch daemon, existing rules are removed. Reset the rules.
To check whether HW offloading is actually used, use ovs-appctl tool while hosts are communicating:
$ ovs-appctl dpctl/dump-flows -m | grep pf0hpf
ufid:e81cbd1d-0120-4ef7-af70-f7a8cdf9ffc2, skb_priority(0/0),skb_mark(0/0),ct_state(0/0),ct_zone(0/0),ct_
mark(0/0),ct_label(0/0),recirc_id(0),dp_hash(0/0),in_port(pf0hpf),packet_type(ns=0/0,id=0/0),eth(src=00:0
0:00:00:00:00/00:00:00:00:00:00,dst=00:00:00:00:00:00/00:00:00:00:00:00),eth_type(0x0800),ipv4(src=0.0.0.
0/0.0.0.0,dst=0.0.0.0/0.0.0.0,proto=0/0,tos=0/0,ttl=0/0,frag=no), packets:174, bytes:17052, used:0.520s,
offloaded:yes, dp:tc, actions:p0
ufid:09bfe098-3319-4fcf-a2eb-be80636ed34e, skb_priority(0/0),skb_mark(0/0),ct_state(0/0),ct_zone(0/0),ct_
mark(0/0),ct_label(0/0),recirc_id(0),dp_hash(0/0),in_port(p0),packet_type(ns=0/0,id=0/0),eth(src=00:00:00
:00:00:00/00:00:00:00:00:00,dst=00:00:00:00:00:00/00:00:00:00:00:00),eth_type(0x0800),ipv4(src=0.0.0.0/0.
0.0.0,dst=10.10.1.1,proto=0/0,tos=0/0,ttl=0/0,frag=no), packets:175, bytes:17812, used:0.520s, offloaded:
yes, dp:tc, actions:pf0hpf
ufid:29e9b8b3-97a5-425e-a602-25f5765bf855, skb_priority(0/0),skb_mark(0/0),ct_state(0/0),ct_zone(0/0),ct_
mark(0/0),ct_label(0/0),recirc_id(0),dp_hash(0/0),in_port(pf0hpf),packet_type(ns=0/0,id=0/0),eth(src=00:0
0:00:00:00:00/00:00:00:00:00:00,dst=00:00:00:00:00:00/00:00:00:00:00:00),eth_type(0x0806),arp(sip=0.0.0.0
/0.0.0.0,tip=0.0.0.0/0.0.0.0,op=0/0,sha=00:00:00:00:00:00/00:00:00:00:00:00,tha=00:00:00:00:00:00/00:00:0
0:00:00:00), packets:1, bytes:38, used:5.820s, dp:tc, actions:p0,ovsbr1,en3f0pf0sf0
Three flows, each of which corresponds to each OvS rule, have been captured by dump-flows.
First flow represents outbound packets (in_port(pf0hpf), actions:p0), second inbound packets (in_port(p0), actions:pf0hpf), and third is arp (eth_type: 0x0806, flooded to all connected ports: p0,ovsbr1,en3f0pf0sf0).
Note that, you can see offloaded:yes, dp:tc in the first and second flow, which means BlueField embedded switch (Eswitch) partially processed traffic control (TC).
Refer to the presentation from Mellanox 3 to see what “partially process” means, and how Eswitch handles offloading.
If you set hw-offload off, you can see the following flows, which don’t have offloaded field:
ufid:240da61d-5cea-4161-9f60-783915bb1a1c, recirc_id(0),dp_hash(0/0),skb_priority(0/0),in_port(pf0hpf),sk
b_mark(0/0),ct_state(0/0),ct_zone(0/0),ct_mark(0/0),ct_label(0/0),eth(src=00:00:00:00:00:00/00:00:00:00:0
0:00,dst=00:00:00:00:00:00/00:00:00:00:00:00),eth_type(0x0800),ipv4(src=0.0.0.0/0.0.0.0,dst=0.0.0.0/0.0.0
.0,proto=0/0,tos=0/0,ttl=0/0,frag=no), packets:18, bytes:1764, used:0.208s, dp:ovs, actions:p0
ufid:a5ff341c-7180-4be2-af6e-2792c4275e70, recirc_id(0),dp_hash(0/0),skb_priority(0/0),in_port(p0),skb_ma
rk(0/0),ct_state(0/0),ct_zone(0/0),ct_mark(0/0),ct_label(0/0),eth(src=00:00:00:00:00:00/00:00:00:00:00:00
,dst=00:00:00:00:00:00/00:00:00:00:00:00),eth_type(0x0800),ipv4(src=0.0.0.0/0.0.0.0,dst=10.10.1.1,proto=0
/0,tos=0/0,ttl=0/0,frag=no), packets:18, bytes:1764, used:0.208s, dp:ovs, actions:pf0hpf
Offload Performance Measurement #
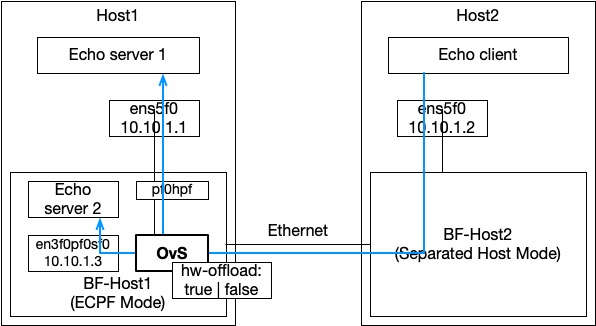
I tried to measure network performance by running simple data echo programs (16B~16MiB). This could quite be inaccurate, better to use iperf, etc. But I wanted to know difference in latency between host-to-host communication and the host-to-SmartNIC communication. Below figure is a configuration.
Note that the following rules should be added to forward packets to a process running in SmartNIC:
# should be the port that is connected to ovs-system, not the one with IP assigned. $ ovs-ofctl add-flow ovsbr1 ip,in_port=p0,ip_dst=<smartnic_ip>,actions=output:en3f0pf0sf0 $ ovs-ofctl add-flow ovsbr1 ip,in_port=en3f0pf0sf0,actions=output:p0
std::tcp for data transfer.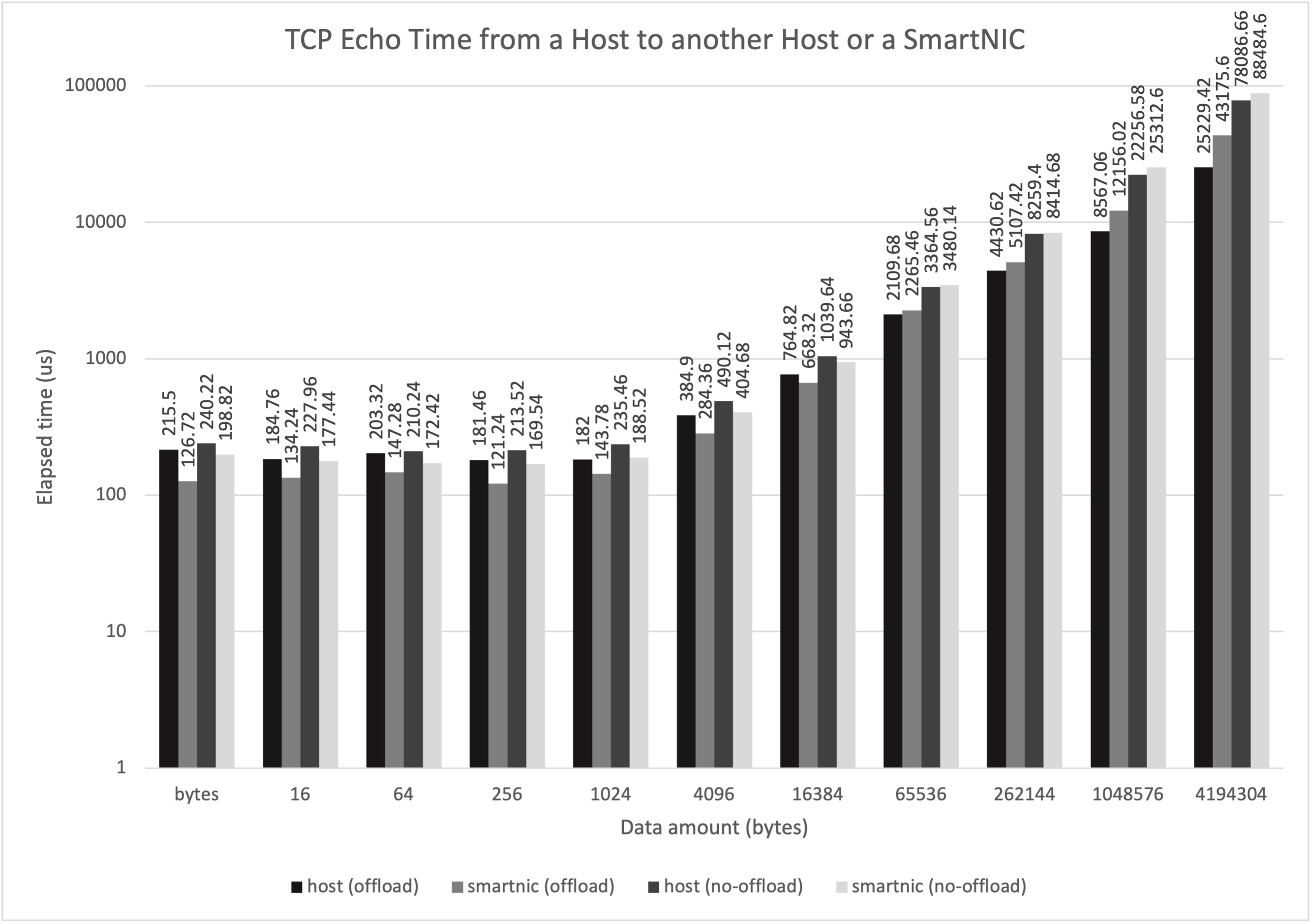
We can see two expected behaviors from the result:
- Communication with the echo server in SmartNIC shows lower latency. This is probably because SmartNIC CPU is much closer than the host CPU to the client, reducing PCIe round trip time in Host 1.
- Using TC-offload provides performance benefit.
while two unexpected outcomes are shown in the result:
- Non-offloaded (SW only) OvS performance is not that bad. The tutorial says there was 88% performance degradation, which is not my case. Not sure what was different. Also, ARM CPUs are still not heavily used during packet processing if I glimpsed.
- SmartNIC performs worse with larger data size (e.g. 25ms in host vs 43ms in BF2 for 4MB TCP echo). I suspect this is because of low performance SmartNIC cores; Linux TCP packet processing performance with BF2 cores is probably the reason?
OVS-DPDK and ASAP2 #
TBD