GPU Resource Management
This post is a study of the paper Operating Systems Challenges for GPU Resource Management (International Workshop on Operating Systems Platforms for Embedded Real-Time Applications, 2011), and Implementing Open-Source CUDA Runtime (Programming Symposium, 2013).
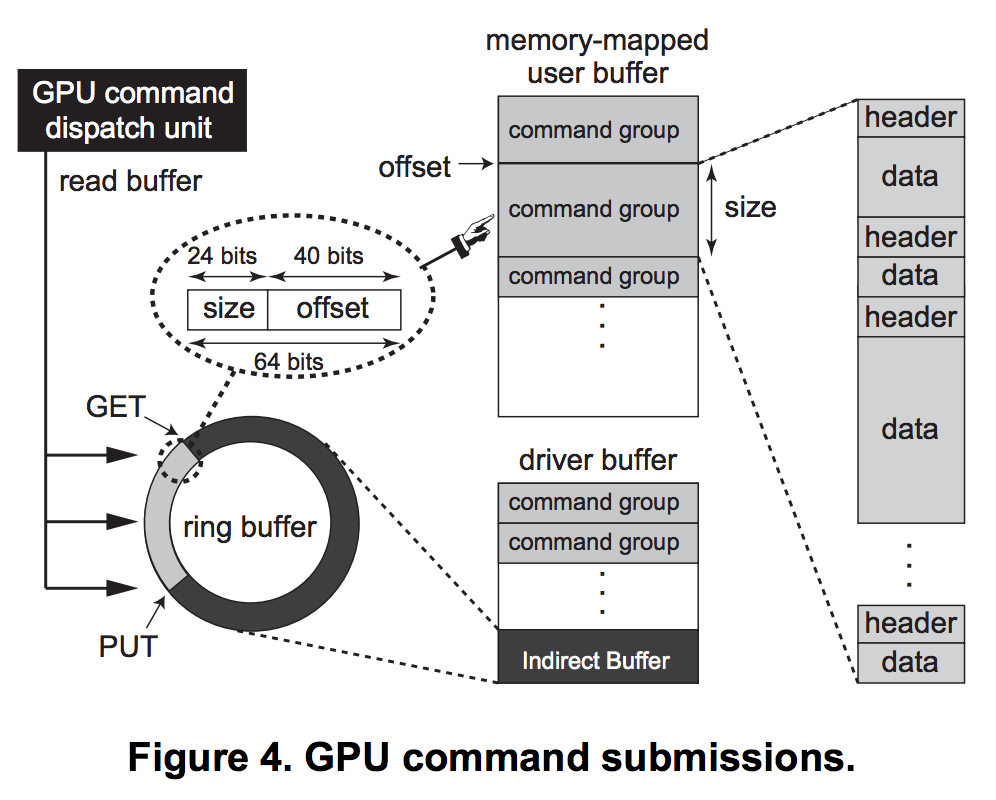
The GPU channel is an interface that bridges across the CPU and the GPU contexts, especially when sending GPU commands from the CPU to the GPU.
GPU channel is the only way to send GPU commands to the GPU. Hence, user programs must allocate GPU channels.
The GPU channel uses two types of buffers to store GPU commands:
- GPU command buffer (also called FIFO push buffer)
- Ring buffer (also called indirect buffer)
When the commands are written to the command buffer, the system writes packets, each of which is a (size, address offset) tuple to locate the corresponding GPU commands, into the indirect buffer.
The GPU reads the indirect buffer instead of the command buffer and dispatches the GPU commands pointed to by the packets.
Following codes are used to write a GPU command into the GPU command buffer.
lib/user/nouveau_gdev.c
void __nouveau_fifo_push(struct gdev_ctx *ctx, uint64_t base, uint32_t len, int flags)
{
struct nouveau_pushbuf *push = (struct nouveau_pushbuf *)ctx->pctx;
int dwords = len / 4;
int p = ctx->fifo.pb_put / 4;
int max = ctx->fifo.pb_size / 4;
nouveau_pushbuf_space(push, dwords, 0, 0);
for (;dwords > 0; dwords--) {
*push->cur++ = ctx->fifo.pb_map[p++];
if (p >= max) p = 0;
}
ctx->fifo.pb_put += len;
ctx->fifo.pb_put &= ctx->fifo.pb_mask;
}
void __nouveau_fifo_update_get(struct gdev_ctx *ctx)
{
ctx->fifo.pb_get = ctx->fifo.pb_put;
printf("%s: pb_get = 0x%x\n", ctx->fifo.pb_get);
}
static inline void __gdev_fire_ring(struct gdev_ctx *ctx)
{
if (ctx->fifo.pb_pos != ctx->fifo.pb_put) {
uint64_t base = ctx->fifo.pb_base + ctx->fifo.pb_put;
uint32_t len;
if (ctx->fifo.pb_pos > ctx->fifo.pb_put) {
len = ctx->fifo.pb_pos - ctx->fifo.pb_put;
} else {
len = ctx->fifo.pb_size - ctx->fifo.pb_put;
ctx->fifo.push(ctx, base, len, 0);
ctx->fifo.pb_put = 0;
base = ctx->fifo.pb_base;
len = ctx->fifo.pb_pos;
}
if (len > 0)
ctx->fifo.push(ctx, base, len, 0);
ctx->fifo.pb_put = ctx->fifo.pb_pos;
if (ctx->fifo.kick)
ctx->fifo.kick(ctx);
}
}
static inline void __gdev_out_ring(struct gdev_ctx *ctx, uint32_t word)
{
while (((ctx->fifo.pb_pos + 4) & ctx->fifo.pb_mask) == ctx->fifo.pb_get) {
uint32_t old = ctx->fifo.pb_get;
//__gdev_fire_ring(ctx);
ctx->fifo.update_get(ctx);
if (old == ctx->fifo.pb_get) {
SCHED_YIELD();
}
}
ctx->fifo.pb_map[ctx->fifo.pb_pos/4] = word;
ctx->fifo.pb_pos += 4;
ctx->fifo.pb_pos &= ctx->fifo.pb_mask;
}
ctx->fifo.push() is a function pointer pointing to __nouveau_fifo_push(), and so does ctx->fifo.update_get to __nouveau_fifo_update_get().
As the paper explained, when the command is written, the system also writes a packet into the indirect buffer. This is done by Nouveau device driver.
nouveau/nouveau_dma.c
/* Fetch and adjust GPU GET pointer
*
* Returns:
* value >= 0, the adjusted GET pointer
* -EINVAL if GET pointer currently outside main push buffer
* -EBUSY if timeout exceeded
*/
static inline int
READ_GET(struct nouveau_channel *chan, uint64_t *prev_get, int *timeout)
{
uint64_t val;
val = nv_ro32(chan->object, chan->user_get);
if (chan->user_get_hi)
val |= (uint64_t)nv_ro32(chan->object, chan->user_get_hi) << 32;
/* reset counter as long as GET is still advancing, this is
* to avoid misdetecting a GPU lockup if the GPU happens to
* just be processing an operation that takes a long time
*/
if (val != *prev_get) {
*prev_get = val;
*timeout = 0;
}
if ((++*timeout & 0xff) == 0) {
udelay(1);
if (*timeout > 100000)
return -EBUSY;
}
if (val < chan->push.vma.offset ||
val > chan->push.vma.offset + (chan->dma.max << 2))
return -EINVAL;
return (val - chan->push.vma.offset) >> 2;
}
void
nv50_dma_push(struct nouveau_channel *chan, struct nouveau_bo *bo,
int delta, int length)
{
struct nouveau_bo *pb = chan->push.buffer;
struct nouveau_vma *vma;
int ip = (chan->dma.ib_put * 2) + chan->dma.ib_base;
u64 offset;
vma = nouveau_bo_vma_find(bo, nv_client(chan->cli)->vm);
BUG_ON(!vma);
offset = vma->offset + delta;
BUG_ON(chan->dma.ib_free < 1);
nouveau_bo_wr32(pb, ip++, lower_32_bits(offset));
nouveau_bo_wr32(pb, ip++, upper_32_bits(offset) | length << 8);
chan->dma.ib_put = (chan->dma.ib_put + 1) & chan->dma.ib_max;
mb();
/* Flush writes. */
nouveau_bo_rd32(pb, 0);
nv_wo32(chan->object, 0x8c, chan->dma.ib_put);
chan->dma.ib_free--;
}
Note that nv_wo32(chan->object, 0x8c, chan->dma.ib_put) writes the value chan->dma.ib_put to the fixed offset of base address of the channel + 0x8c.
e.g. physical address of channel = 0x8e020000: nv_wo32() writes the value at 0x8e02008c.
nv50_dma_push() is the only function that uses ib_put variable.
Initializing indirect buffer is done by nouveau_channel_init() in Nouveau device driver.
static int
nouveau_channel_init(struct nouveau_channel *chan, u32 vram, u32 gart)
{
...
/* initialise dma tracking parameters */
switch (nv_hclass(chan->object) & 0x00ff) {
case 0x006b:
case 0x006e:
...
default:
chan->user_put = 0x40;
chan->user_get = 0x44;
chan->user_get_hi = 0x60;
chan->dma.ib_base = 0x10000 / 4;
chan->dma.ib_max = (0x02000 / 8) - 1;
chan->dma.ib_put = 0;
chan->dma.ib_free = chan->dma.ib_max - chan->dma.ib_put;
chan->dma.max = chan->dma.ib_base;
break;
}
...
}
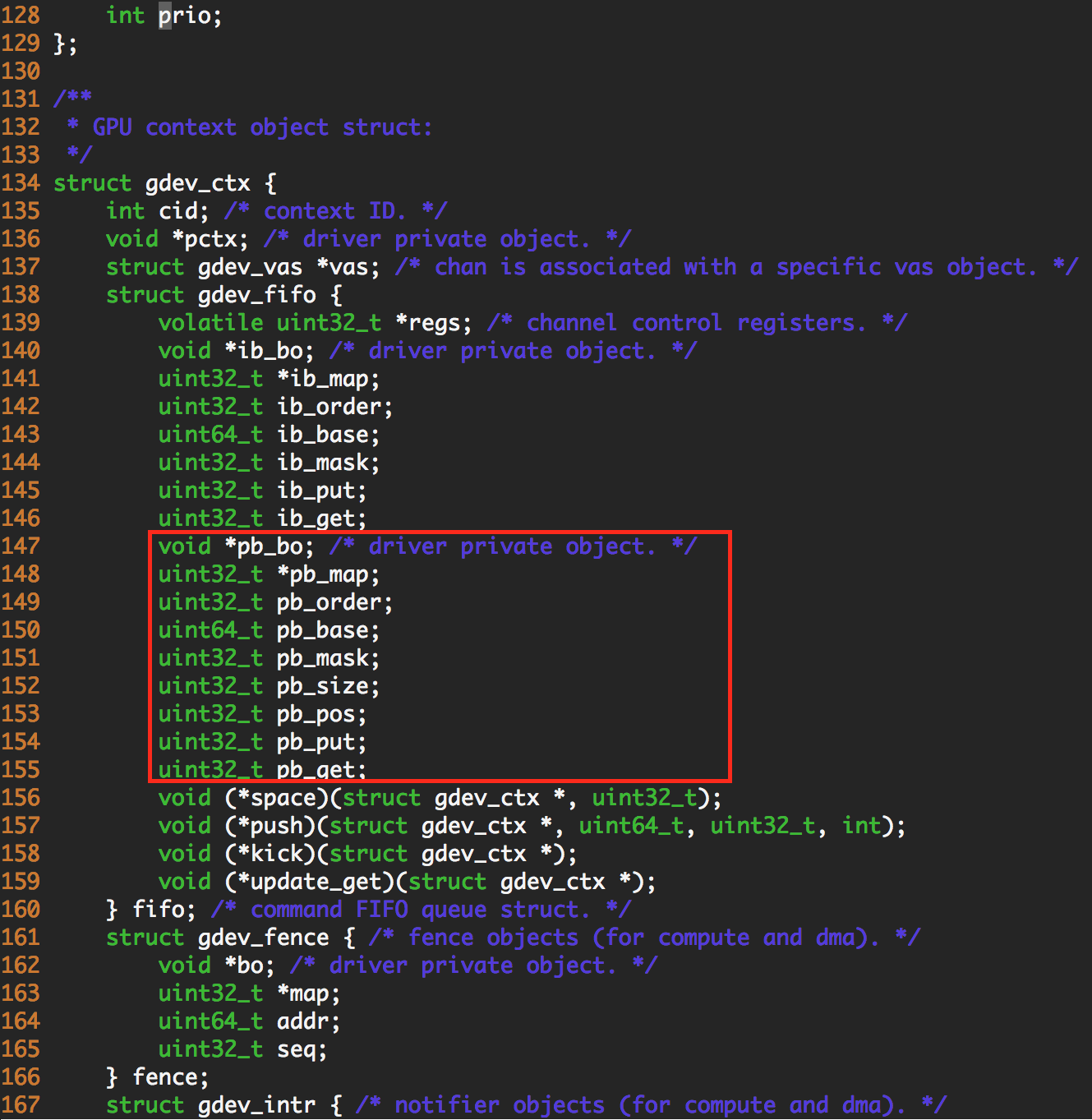
What make me confused is that struct gdev_ctx has not only pb, but also ib variables, so user space API also initializes these.
struct gdev_ctx *gdev_raw_ctx_new(struct gdev_device *gdev, struct gdev_vas *vas)
{
struct gdev_ctx *ctx;
...
ctx = malloc(sizeof(*ctx));
memset(ctx, 0, sizeof(*ctx));
...
/* FIFO push buffer setup. */
ctx->fifo.pb_order = 15;
ctx->fifo.pb_map = push_bo->map;
ctx->fifo.pb_bo = push_bo;
ctx->fifo.pb_base = push_bo->offset;
ctx->fifo.pb_mask = (1 << ctx->fifo.pb_order) - 1;
ctx->fifo.pb_size = (1 << ctx->fifo.pb_order);
ctx->fifo.pb_pos = ctx->fifo.pb_put = ctx->fifo.pb_get = 0;
ctx->fifo.space = __nouveau_fifo_space;
ctx->fifo.push = __nouveau_fifo_push;
ctx->fifo.kick = __nouveau_fifo_kick;
ctx->fifo.update_get = __nouveau_fifo_update_get;
/* FIFO index buffer setup. */
ctx->fifo.ib_order = 12;
ctx->fifo.ib_map = NULL;
ctx->fifo.ib_bo = NULL;
ctx->fifo.ib_base = 0;
ctx->fifo.ib_mask = (1 << ctx->fifo.ib_order) - 1;
ctx->fifo.ib_put = ctx->fifo.ib_get = 0;
...
}
This variable is used by the function gdev_fifo_push() in gdev_nvidia_fifo.c code, but this is used when gdev is running as a kernel mode.
struct gdev_ctx *gdev_raw_ctx_new(struct gdev_device *gdev, struct gdev_vas *vas)
{
struct gdev_ctx *ctx;
...
crx = kzalloc(sizeof(*ctx), GFP_KERNEL);
...
/* command FIFO. */
ctx->fifo.regs = chan.regs;
ctx->fifo.ib_bo = chan.ib_bo;
ctx->fifo.ib_map = chan.ib_map;
ctx->fifo.ib_order = chan.ib_order;
ctx->fifo.ib_base = chan.ib_base;
ctx->fifo.ib_mask = chan.ib_mask;
ctx->fifo.ib_put = 0;
ctx->fifo.ib_get = 0;
ctx->fifo.pb_bo = chan.pb_bo;
ctx->fifo.pb_map = chan.pb_map;
ctx->fifo.pb_order = chan.pb_order;
ctx->fifo.pb_base = chan.pb_base;
ctx->fifo.pb_mask = chan.pb_mask;
ctx->fifo.pb_size = chan.pb_size;
ctx->fifo.pb_pos = 0;
ctx->fifo.pb_put = 0;
ctx->fifo.pb_get = 0;
ctx->fifo.push = gdev_fifo_push;
ctx->fifo.update_get = gdev_fifo_update_get;
...
}
Therefore, it is reasonable to say that __nouveau_fifo_push() is used for user space gdev, and gdev_fifo_push() is used for kernel space gdev.
The difference is that, push buffer is allocated in user space in user space gdev, and allocated in kernel space in kernel space gdev.
The same thing is that index buffer (indirect buffer) is allocated in kernel space. In case of user space gdev, indirect buffer is managed by libdrm, not Nouveau or gdev.